Kafka Producer Concepts
Review of the producer concepts in Apache Kafka.
Kafka is a distributed, resilient, fault tolerant streaming platform that works with high data throughput. In this page, the main concepts of Kafka Producer technology will be covered.
- What is a Producer?
- Primary Methods to Send Messages
- Possible Errors When Sending Messages to Kafka
- Acknowledgments
- Message Keys
- Idempotent Producer
- Retrying mechanism (to prevent messages to be lost)
- Compression of messages
- Batch of messages
- Message Buffering and Blocking of .send()
- Delivery Semantics for Producers to Consumers
- Demo Code: Java Producers
- CLI: important commands to know
- References
What is a Producer?
Producer is a specific type of Kafka client, responsible to send data to Kafka Broker for writing.
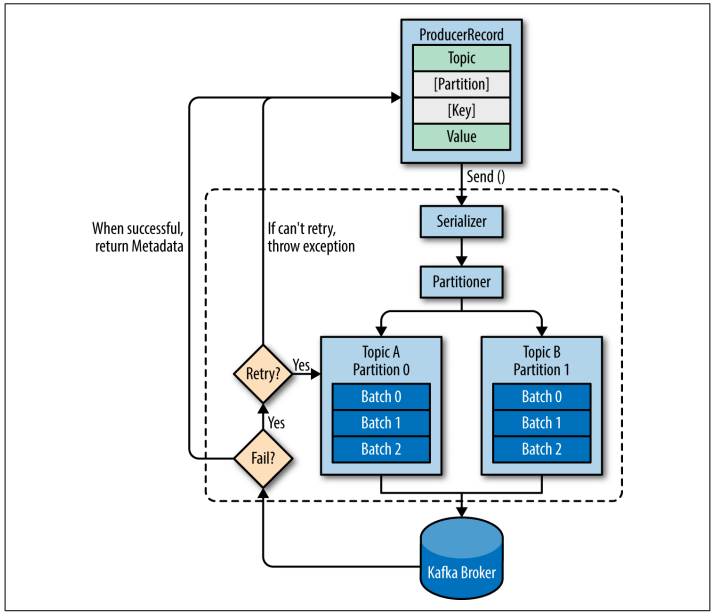
The following diagram was taken from Kafka: The Definitive Guide book:
Figure: Kafka Producer High Level Overview
In order to create a message, one must create a ProducerRecord with topic and value information (partition and key are also important, but not required). Message is then serialized (key and value) and then the Partitioner algorithm define to which partition data will be sent (more on that later). Data is then saved in batches of data that goes to the same partition. Only after that, data is actually send to the broker.
If broken write fails, Kafka Producer can retry. If still fail after retry, an exception is thrown.
- Producers know to which partition and broker to send messages, because of the metadata provided by the brokers.
- Producer is able to recovery automatically if broker fails, because of the re-election of a leader, performed by Kafka Cluster. Producer will receive metadata with the new leader definition for a topic - and this leader is the one that will now receive the data.
In order to understand much of the basic concepts here described, it is mandatory to understand Kafka Core concepts. Those concepts can be found in details in the Kafka Core Concepts’ page.
Primary Methods to Send Messages
fire-and-forget: data is sent without any confirmationsynchonous send: the send() method returns a Future object with RecordMetadata, and then the get() method is used to block until returnasynchronous send: the send() method is used with a callback function, to perform something over RecordMetadata when the request returns (and nothing is blocked)
The usage can be improved this way: you can start with a single producer and an synchronous method. If throughput increase is required, you can make the method async, increasing threads. If throughput limit is reached, then you can increase the number of different producers.
Possible Errors When Sending Messages to Kafka
Kafka Producer has two types of erros:
Retriable errors: are those that will happen but Kafka Producer will stil retry (for instance, a partition is being rebalanced in the broker)Non-retriable errors: errors that could not be resolved by retrying (for instance, “message size too large”). In that case, errors will be thrown immediately.SerializationException: when it fails to serialize a messageBufferExhaustedException: when the buffer is fullTimeoutException: when the buffer is fullInterruptException: when the sending thread is interrupted
Acknowledgments
When Kafka Producer send data to the broker, it must receive a confirmation that the data was properly received. This is called acknowledgment.
The acknowledgement can be of the the following types:
acks=0: no acknowledgment. Client do not expect any confirmation from the Broker. It just don’t care. There is a risk of losing messages. It is ideal in cases in which data loss is not critical (metrics and logs).acks=1: leader acknowledgment. This is the default. Client expects that only the partition leader to send confirmation, and not cares about the ISRs. It is more secure thanacks=0in terms of data consistency, but still can lose messages (if leader was down before message can be replicated)acks=all: all brokers’ replicas of a topic (leader and ISRs) must confirm that the message was received. This is the slowest method, but much more secure in terms of data consistency, since no data is lost. This property must be used together withmin.insync.replicas.min.insync.replicas: this is the minimal number of ISR (Leader and replicas) that must acknowledge the message in order to considerall. In fact, “all” is not the case (but this value instead). This property may be set in broker or topic level (topic overrides broker definition).- A
NotEnoughReplicasexception will be thrown if the number of replicas that acks the message is less than this parameter value. - For instance, consider a
replicationFactor=3,min.insync.replicas=2andacks=all: the cluster for that particular topic can tolerate a maximum of 1 broker down. Otherwise, theNotEnoughReplicasexception will be thrown
To set min.insync.replicas:
- In broker: add property in the
config/server.propertiesfile - In a existing topic: execute the following command:
$ kafka-config.sh --bootstrap-server localhost:9092 --topic mytest --add-config min.insync.replicas=2 --alter
Message Keys
- A message key can be string, number, object, etc - anything.
- If a message key is a
nullvalue, Producer’s Round Robin Partitioner will decide to which partition to send data. If it was decided that message must go toPartition1, Kafka Producer now check in metadata for who is the broker that is the Leader ofPartition1. Then, the data is directly sent to that broker’ partition. - If a message key is a
non-nullvalue, then a Producer’sMurmurHash2algorithm will define to which partition to send that message, based on the number of partitions of a topic and the key. After that, every message that have the same key will go to the same partition (since the hash is always the same for these constant attributes).
The formula of key partitioning is defined in DefaultPartitioner.java class as the following:
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
Kafka’s DefaultPartitioner class in Github | Kafka’s Utils class in Github
Kafka message keys is how Kafka ensures the order of messages in a topic, and this is why is important to keep the same number of partitions for a topic once defined (otherwise, the formula below will return different values, and data with same key will be sent to different partitions).
So, there is two partitioners being used: Round Robin Partitioner (if keys are not informed) and Default Partitioner (if keys are informed - in which case uses murmur2 for decision). Both classes implement Partitioner interface. If you want to change the behavior of partitioning, you can write your own implementation of Partitioner.
Idempotent Producer
In distributed applications, it’s always possible that data will be duplicated because of network issues. In Kafka, message duplication may happen like this:
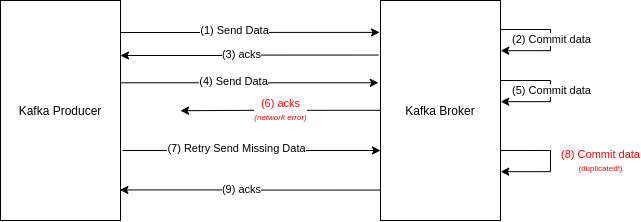
Figure: Kafka messages’ duplication scenario
In order to prevent that, the concept of Idempotent Producer was introduced. A Idempotent Producer ensures that only one sent message will be received and accepted by the broker.
The concept of Idempotent Producer was implemented in Kafka 0.11. Now, Kafka Broker will detect if a message is duplicated and do not commit it. For this to work, both producer and broker must be at version >= 0.11, and the property enable.idempotence=true must be set at client-side (producer). Nothing is required at broker level, in this regard.
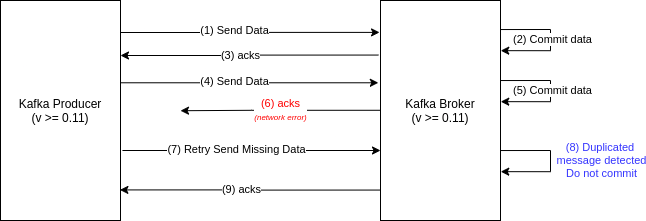
Figure: Kafka Idempotent Producer avoiding message duplication
The definition of enable.idempotence=true only works if three other properties are set accordingly:
retries > 0: the maximum number of re-attemptsmax.in.flight.requests.per.connection <= 5(Kafka >= 1.0): the number of requests a client will send in a single connection before blocking. Kafka can ensures high performance and still keep the order even if in parallel. More information can be found in KIP-5494
The maximum supported requests per connection in idempotent mode is 5, according to this documentation. This number can be bigger, but exacly-once semantics are not guaranteed.
acks=all: both Leader and ISR must ensure that the message is received.
If any of the previous properties are not explicitly set, the enable.idempotence=true property will ensure suitable values for them, as follows:
retries=<Integer.MAX_VALUE>max.in.flight.requests.per.connection=5acks=all
Retrying mechanism (to prevent messages to be lost)
In case of failures (no acks returned), a message need to be resend or will be lost. Kafka Producers do this automatically - and the retries property is important to define the behavior (the number of re-attempts to perform).
- Kafka <= 2.0: retries = 0 per default
- Kafka >= 2.1: retries = Integer.MAX_VALUE per default
Other properties in this regard are also important to consider:
retry.backoff.ms=100(default): The time (in milisseconds) in which Kafka Producer will wait til resend the message to Kafka Broker again. Since the retry property if very big, it is also important to define a timeout.delivery.timeout.ms=120000(default): Time time (in milisseconds) until timeout occurs and message is discarded. Default is two minutes. So, according to the defaults, a message will be resend at each 100ms for two minutes until Kafka Producer give it up. An exception will be thrown for the Producer to catch, that will indicate that a message acknowledge could not be get during the timeout period.max.in.fligh.requests.per.connection: This is the number of messages that aproducer.send()method sends in parallel. A default value is 5, but in the case of retries, this may generate messages out of order. To ensure order, one must set this property as 1, but throughput will then be compromised. The best approach is to useenable.idempotence=true, that allows the default value of 5 for this property and ensure ordering at the same time, by using metadata information in the message header.
All this retrying mechanism is better handled if using the concept of Idempotent Producers, previously described. If using Idempotent Producer, your producer can be considered safe.
Compression of messages
Is this concept, a bunch of messages is grouped together (as a batch) in a producer before be send to the broker.
- Since each message has a body and a header, the approach to compress messages in a batch of messages offers benefits in size, because now several messages share the same header (instead of duplicate a header for each message). The compression also helps when the body of a message is a big text (such as JSON payloads, for instance).
- In terms of throughput, it also offers improvement, since reduces the number of requests that have to be made to a bunch of messages reach the broker.
- The compressed message (a message with a bunch of messages) is saved as-it-is in the broker, and only de-compressed in the consumer. The broker do not know if a message is compressed or not.
Compression is more effective according to the number of messages being sent.
The property that defines compression is compression.type and can assume the following values:
none: defaultgzip: strong compression, but at a cost of more time and cpu cycleslz4: less compression than gzip, but very fastsnappy: offers a balance between gzip and lz4
Compression Advantages
latency: faster to transfer data in networkthroughtput: increased number of messages sent together per requestdisk: better utilization of storage
Compression Disadvantages
CPU at clients: producers and consumers will have to use cpu cycles in order to compress and decompress data.
Compression Overall
- Since distributed applications’ number 1 issue is network, it is important to compress messages, even if CPU usage will increase at client-side.
- Brokers do not suffer anything, with ou without compression, so that is nothing to worry about in terms of any effect in the cluster.
- Adopt
lz4orsnappycompression types to the best balance between compression ratio and speed
Batch of messages
When using max.in.flight.requests.per.connection=5, Kafka producer will use 5 threads to send 5 different messages at a time. While the acks for those message do not return, Kafka Producer will start batching the next messages.
This kind of “background batching” improves latency (messages reduced in size) and throughtput (more messages per request are being sent).
The batch mechanism do not need any action in the broker side, and only need to be configured on the producer side.
linger.ms(default: 0): this is the number of milisseconds that Kafka will wait until send data. During this period of time, messages will be grouped as a batch.- by adding a little delay (for instance,
linger.ms=5), we can improve throughtput (more messages being sent per request), compression (since data is better compressed with more messages) and efficiency of producers
- by adding a little delay (for instance,
batch.size(default: 16KB): this is the maximum number of bytes that will be included in a batch. To increase the batch size to 32KB or even 64KB can improve compression, throughput and efficiency of requests.- any message bigger than the batch size will be send individually (and not as part of any batch)
- batch is allocated per partition
- if
batch.sizeis reached beforelinger.mstime has passed, batch is sent immediately.
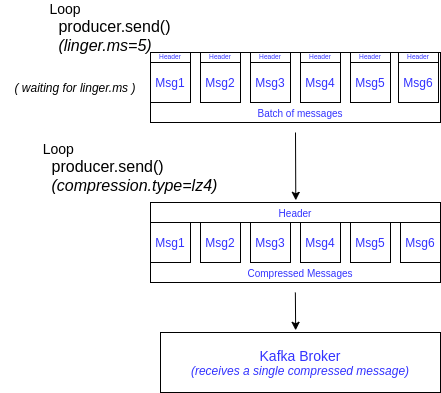
Figure: Kafka Batch and Compression of messages
Message Buffering and Blocking of .send()
Message batches are stored in a producers’ internal buffer. This buffer has a limited size, that must be considered.
buffer.memory(default: 33554432 bytes=> 32MB): this is the buffer size for all partitions batches in the producer. It will be filled and flushed according to the throughput. If it gets full, thesend()method will block, waiting for data to be flushed, so the buffer can be cleared.max.block.ms(default: 60000ms => 1 min): this is the time that thesend()method will block until throws an exception. An exception can happen if the producers’ buffer is full or if broker is not accepting any new messages.
Delivery Semantics for Producers to Consumers
- at most once: offsets are commited as soon as messages are received by the broker. If the consumers are down, messages may be lost. That is because a consumer recovery process will start reading data from the latest commited offset, hence the previous commited but unread data in this delta of time will be ignored.
- This method is better applied in cases where it is acceptable to lose messages (for instance, metrics and log data - related to
acks=0in that regard).
- This method is better applied in cases where it is acceptable to lose messages (for instance, metrics and log data - related to
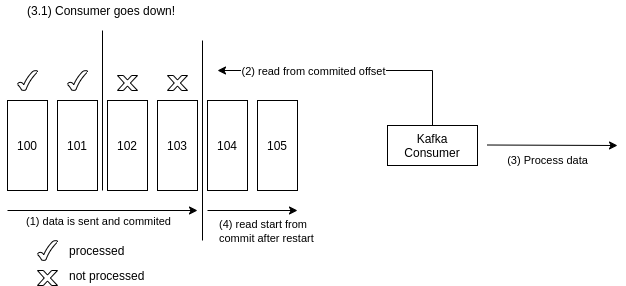
Figure: Kafka Delivery Semantics: At Most Once
- at least once (default): offsets are commited after message is processed. If consumer goes down after processing but before commit offsets, messages will be consumed from the last commit point, and this can result in duplicate messages being processed.
- To avoid this behavior, the consumer must be idempotent. More on that on the Kafka Consumer Concepts’ page.
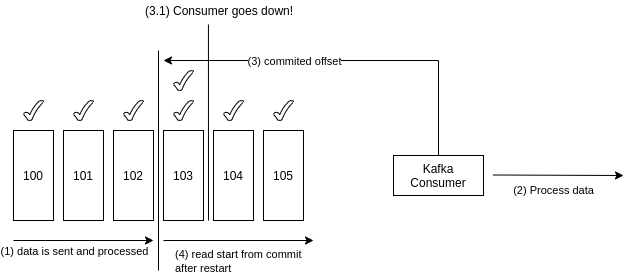
Figure: Kafka Delivery Semantics: At Least Once
- exactly once: this behavior ensures that only one message will be processed. It can only be achieved from Kafka to Kafka.
Demo Code: Java Producers
Simple Producer
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class SomeProducer {
public static void main(String[] args) {
// define basic (and mandatory) properties: bootstrapServer,
// key serializer and value serializer
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// serializers must implement org.apache.kafka.common.serialization.Serializer interface
// Kafka provide ByteArraySerializer, IntegerSerializer and StringSerializer
// If common case is not the case, you have to provide your own, or use from others,
// like AvroSerializer.
// key serializer is required even if key is not being used!
// key.serializer
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// value.serializer
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// create a record (message)
ProducerRecord<String, String> record = new ProducerRecord<String, String>("helloworld_topic", "hello world message");
// create a producer (using defined properties) and send message
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
producer.send(record);
producer.close();
}
}
Simple Producer (with Keys and Callback)
Some observations about the following code:
- message callback allow us to check for metadata sent by the broker
- the
.get()method is called to force synchronous requests, meaning that only one message will be sent at a time (and the next will be sent only after ack will be returned by the broker and received). It’s being used here to better check results in the log, and should not be used this way in production. Without a.get()method call, the behavior is to run the number of threads defined inmax.in.flight.requests.per.connectionproperty.
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class SomeProducerWithKey {
public static void main(String[] args) throws ExecutionException, InterruptedException {
final Logger logger = LoggerFactory.getLogger(SomeProducerWithKey.class);
// define basic properties
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// producer is defined once to be called 100 times
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 100; i++) {
// preparing recordo to be send
String topic = "helloworld_topic";
String key = "id_" + i;
String value = "hello world: " + i;
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, key, value);
logger.info("topic: {}, key: {}, value: {}", topic, key, value);
// sendind record; now, we can see metadata as a result
// class implements org.apache.kafka.clients.producer.Callback
// interface with a single method onCompletion()
producer.send(record, (recordMetadata, e) -> {
if (e == null) {
logger.info("Received new metadata: \n" +
"Topic: " + recordMetadata.topic() + "\n" +
"Partition: " + recordMetadata.partition() + "\n" +
"Offset: " + recordMetadata.offset() + "\n" +
"Timestamp: " + recordMetadata.timestamp());
} else {
logger.error("Error while producing message.", e);
}
}).get(); // with this method, execution is synchronous (one a at time)
}
producer.flush();
producer.close();
}
}
Simple Producer (with safe and throughput properties)
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.record.CompressionType;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class ProducerDemo {
private static Properties properties() {
Properties props = new Properties();
// basic properties
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // bootstrap.servers
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // key.serializer
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // value.serializer
// safe/idempotent producer properties
props.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true"); // enable.idempotence
props.setProperty(ProducerConfig.ACKS_CONFIG, "all"); //acks
props.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, "5"); // max.in.flight.requests.per.connection
props.setProperty(ProducerConfig.RETRIES_CONFIG, Integer.toString(Integer.MAX_VALUE)); // retries
// high throughput producer properties
props.setProperty(ProducerConfig.LINGER_MS_CONFIG, "20"); // linger.ms
props.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, CompressionType.SNAPPY.name()); // compression.type
props.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, Integer.toString(32 * 1024)); // batch.size; 32KB batch size
return props;
}
public static void main(String[] args) {
String topic = "helloworld_topic";
String messageValue = "hello world";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, messageValue);
KafkaProducer<String, String> producer = new KafkaProducer<>(properties());
producer.send(record);
producer.close();
}
}
CLI: important commands to know
Producing messages from a file
file: input-messages.txt
1,message1
2,message2
3,other message
$ ./kafka/bin/kafka-console-producer.sh --broker-list localhost:9092
--topic sometopic --property parse.key=true --property key.separator=,
< input-messages.txt
Producing several messages at once
$ ./kafka/bin/kafka-console-producer.sh --broker-list localhost:9092
--topic sometopic << EOF
Message 01
Message 02
Message 03
EOF
Using this command, all three messages will be sent only after EOF is hit, and Kafka Console Producer shell will then terminate its execution.
Change min.insync.replicas from an existing topic
$ kafka-config.sh --bootstrap-server localhost:9092 --topic sometopic
--add-config min.insync.replicas=2 --alter