Kafka ksqlDB Concepts
Review of ksqlDB concepts in Apache Kafka.
Kafka is a distributed, resilient, fault tolerant streaming platform that works with high data throughput. In this page, the main concepts of Kafka KSQL technology will be covered.
- ksqlDB Overview
- Push and Pull Queries
- How to Run
- ksqlDB Main Commands
- Showing Topics and their Data
- Creating a Stream
- Showing the Details of new Streams
- Select Query Stream
- Query Streams with Limits
- Aggregate Function: COUNT
- Deleting a Stream
- Generating Synthetic Data
- ksqlDB Build-In Functions
- Creating a New Stream Based on Existing Stream
- Creating a New Stream (From File) Based on Existing Stream
- Delete a Stream with a Running Query
- Creating a Table and Querying It
- Tables in ksqlDB
- Joins (for Streams and Tables)
- Complete Example: Create, Populate, Aggregate and Get Data
- Windowing
- State Stores
- Functions
- KSQL Deployment Choices
- Query Explain Plan
- Scaling, HA and Load Balancing
- Using Kafka Connect with ksqlDB
- Data Encodings
- Data Structures: Nested JSON
- References
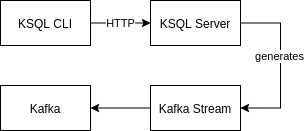
ksqlDB Overview
Figure: ksqlDB Overview.
According to Confluent page, ksqlDB is a streaming mechanism that enables real-time processing against Kafka. It provides an intuitive SQL-like interface to manage stream processing, and this approach avoids the burden of write Kafka Streams code (in Python of Java). It allow us to perform a very broad range of operations, such as data filtering, transformations, aggregations, joins, windows and session handling.
Kafka ksqlDB is not part of Apache Kafka distribution. You have to download Confluent dist in order to have it.
Push and Pull Queries
Kafka ksqlDB works with queries. In that regard, there are two types of queries to consider and to understand:
- Push Queries: Query the state of the system in motion (real-time) and continue to output results until they meet a LIMIT condition or are terminated by the user.
- These are the most common queries (and default from ksqlDB 5.3 onwards)
EMIT CHANGESclause is required for this type of query since ksqlDB 5.4 onwards.
- Pull Queries: Query the current state of the system, return a result, and terminate.
- These are materialized aggregate tables, which are those created by a
CREATE TABLE AS SELECT <fields>, <agg functions> FROM <sources> GROUP BY <key>kind of statement. - It is required to performs queries on it with rowkey
- These are materialized aggregate tables, which are those created by a
How to Run
- Start Zookeeper and Kafka in Apache Kafka distribution, as usual
- Download Confluent Kafka (required to run ksqlDB)
- Please note that
confluent/etc/ksqldb/ksql-server.propertiesfile is configured to listen to port8088and to connect at Kafka Cluster in0.0.0.0:9092. Change this values right now if they are not suitable to your Kafka installation
- Please note that
- Execute the following commands in Confluent distribution directory:
$ cd ~/confluent
# starting server
[confluent]$ ./bin/ksql-server-start ./etc/ksqldb/ksql-server.properties
# running CLI - inform http protocol or it will not work
[confluent]$ ./bin/ksql http://localhost:8088
Configuring ksqlDB CLI
Settings in ksqlDB can be configured in session level or server level.
- Server level:
./etc/ksqldb/ksql-server.propertiesfile - Session level: There are some available options:
- to use
SETcommand - to adopt config file when ksqlDB session is created:
[confluent $] ./bin/ksql-server ./etc/ksqldb/ksql-server.properties \ --config-file /path/to/config/file
- to use
In order to check configuration variables, one can type in ksqlDB CLI:
ksql> list properties;
More information about ksqlDB CLI starting can be found here.
ksqlDB Main Commands
Somes things to consider regarding ksqlDB commands in CLI:
- ksqlDB commands and queries are case-insensitive
- All statements end with semicolon (;)
Showing Topics and their Data
# list existing topics
ksql> list topics;
ksql> show topics;
# print topic data
ksql> print <topicname>;
ksql> print <topicname> from beginning;
ksql> print <topicname> from beginning limit 2;
ksql> print <topicname> from beginning interval 2 limit 2;
Creating a Stream
When creating a Stream, the ROWTIME (bigint) and ROWKEY (varchar) fields will be implicitly created.
In order for the streams to be properly created, the related topics must exist prior to the stream creation.
ksql> create stream users_stream (name VARCHAR, countrycode VARCHAR)
with (KAFKA_TOPIC='users', VALUE_FORMAT='DELIMITED');
ksql> create stream userprofile_stream (userid INT, firstname VARCHAR, lastname
VARCHAR, countrycode VARCHAR, rating DOUBLE)
with (KAFKA_TOPIC='userprofile', VALUE_FORMAT='JSON');
- “DELIMITED” means CSV data (comma-delimited values)
- Another supported value=”JSON”: in that case, JSON object fields are mapped to stream fields
- Keyworks may be written in lowercase as well
Showing the Details of new Streams
ksql> list streams;
or
ksql> show streams;
ksql> describe 'users'; # to see stream fields and data types
ksql> describe extended 'users'; # to see stream in detail
Select Query Stream
By default, print of data in topics and select queries adopt latest consumption of data (so, only new data are shown). But this behavior can be changed by using SET/UNSET directives, as below:
ksql> set 'auto.offset.reset'='earliest';
ksql> select name, countrycode from users_stream
emit changes;
ksql> unset 'auto.offset.reset';
Query Streams with Limits
ksql> select * from users_stream emit changes limit 2;
Using limit, query is finalized when amount or records are reached. Without it, this is a unbonded stream that only ends with CTRL+C.
- auto.offset.reset=’latest’ + limit: it only ends when new data arrives until the defined limit; in this meantime, CLI remains waiting/blocking
- auto.offset.reset=’earliest’ + limit: start reading messages and leaves as soon as the limit is reached
Aggregate Function: COUNT
ksql> select countrycode, count(*) as countries_count from users_stream
group by countrycode
emit changes;
Deleting a Stream
ksql> drop stream if exists users_stream delete topic;
Generating Synthetic Data
Usually, it’s useful to generate synthetic data for testing purposes. ksqlDB has a tool to do it, called ksql-datagen.
The basic syntax is the following:
[confluent]$ ./bin/ksql-datagen schema=path/to/.avro/file format=JSON \
topic=topic_name key=topic_key_name iterations=10
Iterations refer to the maximum number of records to be generated.
ksqlDB Build-In Functions
There are two type of ksqlDB built-in functions:
- Scalar Functions: get one or more values and returns one or more values (map)
- Aggregation Functions: aggregate stream list values
Creating a New Stream Based on Existing Stream
To create a new stream based on the query of another stream:
ksql> create stream weatherraw with (value_format='AVRO') as
select city->name as cityname, description from weather;
Creating a New Stream (From File) Based on Existing Stream
Let’s consider the file user-profile-pretty.sql:
set 'auto.offset.reset'= 'earliest';
create stream user_profile_pretty as
select firstname + ' ' + ucase(lastname) + ' from ' + countrycode + ' has
a rating of ' + cast(rating as varchar) + ' stars. ' +
case
when rating < 2.5 then 'Poor'
when rating between 2.5 and 4.2 then 'Good'
else 'Excellent'
end
as description
from user_profile_stream emit changes;
unset 'auto.offset.reset';
This second stream (user_profile_pretty) remains bounded to the first (user_profile_stream), with a running query; if the second stream is stopped, the first stop to work, as expected.
To run this file from ksqlDB CLI, we can just run:
ksql> run script '/path/to/file/user-profile-pretty.sql'
Delete a Stream with a Running Query
The user_profile_pretty stream is running and we want to delete it. The steps are below described:
ksql> terminate <query ID>
ksql> drop stream if exists user_profile_pretty delete topic;
As pointed, query must be deleted before the stream.
Creating a Table and Querying It
-- table as a aggregated view of current data
ksql> create table countryDrivers as select countryCode, count(*) as numDrivers
from driversLocation group by contryCode;
-- tables must be queried with rowKey
ksql> select countrycode, numDrivers from countryDrivers where rowKey='BR';
Tables in ksqlDB
Streams are a continuum of data in time. Tables, in the other hand, represent the state of data right now.
Records relate with table two different ways:
- add new records: when there is no records with the same key
- update existing records: when new data has the same key as previous data
The offset earliest concept do not apply for tables, because each query always brings the complete and final state for each key in general, regardless of offset position.
Joins (for Streams and Tables)
The Join mechanism is similiar from database, but with differences because of the type of data (streams and tables).
Streams and Tables can be joined in the following way:
- Stream + Stream => Stream
- Table + Table => Table
- Stream + Table = Stream
Join Requirements
In order to be joined, two objects (Stream or Table) must have the following characteristics:
- Co-partitioned data:
- Input records must have the same number of partitions at both sides
- Key must exists at both sides
- For Tables only:
- Key must be varchar/string
- Message key must have the same content as defined in Key column
Rekeyed Table
In order to perform joins, a stream must have a key. What happens if a stream do not have a key?
A new rekeyed stream must be created from the original one, and the partition by clause must be included:
ksql> select rowKey, city_name from weatherraw -- rowKey is null
ksql> create stream whatherrekeyed as
select * from weatherraw partition by city_name -- city_name is the key now
ksql> select rowKey, city_name from whatherrekeyed -- rowKey is city_name value
-- and now a table can be created:
ksql> create table weathernow with (kafka_topic='weatherrekeyed',
value_format='AVRO', key='city_name')
First Join
Joining a Stream and a Table (Stream + Table => Stream):
select * from userprofile up
left join contrytable ct
on ct.countrycode = up.countrycode;
The command describe extended can be used to check this new stream details.
Repartition a Stream
Joins require that related topics are co-partitioned. That means all the topics related to the streams must have the same number of partitions.
But it is normal that different streams are created with a different number of partitions. Therefore, when it is required to perform a join using those streams, it is first necessary to repartition them to have the same number of partitions.
The strategy for repartition is: create a new stream based on the original stream, forcing the number of partitions of this new stream. Behind the scenes, what happens is that a new topic is created with the desired partitions for it.
ksql> create stream driverprofile_rekeyed with (partitions=1) as
select * from driver_profile partition by driver_name;
-- lets validate our assumptions
ksql> describe extended driverprofile_rekeyed;
ksql> describe extended driver_profile;
Merge Streams
Merge joins two streams as one.
ksql> insert into some_stream select * from another_stream;
- Streams must be of the exact same schema
- Two or more streams can be combined
For instance, let’s populate two topics (some_t and other_t) with data:
[confluent]$ ./bin/ksql-datagen schema=path/to/.avro/file format=JSON \
topic=some_t key=id iterations=10
[confluent]$ ./bin/ksql-datagen schema=path/to/.avro/file format=JSON \
topic=other_t key=id iterations=10
Now, let’s create two independent streams to bind to those topics:
ksql> create stream a_stream with (KAFKA_TOPIC='some_t', value_format='AVRO');
ksql> create stream b_stream with (KAFKA_TOPIC='other_t', value_format='AVRO');
Now, let’s merge them in a brand new stream:
ksql> create stream merge_ab as select 'Some', * from a_stream;
ksql> insert into stream merge_ab select 'Other', * from b_stream;
ksql> select * from merge_ab emit changes;
Complete Example: Create, Populate, Aggregate and Get Data
-- 1. create a stream
ksql> create stream driversLocation (driverId integer, countryCode varchar,
city varchar, driverName varchar)
with (kafka_topic='drivers_location', value_format='JSON', partitions='1');
-- 2. populate stream with data
ksql> insert into driversLocation (driverId, countryCode, city, driverName)
values (1, 'BR', 'Sao Paulo', 'Joao');
ksql> select * from driversLocation emit changes;
-- 3. create an aggregated table
ksql> create table contryDrivers as
select countryCode, count(*) as numDrivers from driversLocation
group by countryCode;
-- run pull query (returns immediately)
ksql> select countryCode, numDrivers from countryDrivers where rowKey='BR';
Windowing
Windowing concepts may be found at the “Kafka Streams Concepts” page in this same blog. The concepts declared there are the same for ksqlDB.
Once windows are defined, what can be done with them?
- Aggregate data (such as
count) - Group data (
group) - Map a field as an array (
collect_list) - Get the highest frequency rate of a field (
topk) - See the window limits (
windowStartandwindowEnd)
Some examples are found below:
-- total of users in 60 seconds
ksql> select city_name, count(*) from world
window tumbling (size 60 seconds)
group by city_name;
-- list of users in 60 seconds
ksql> select city_name, collect_list(user) from world
window tumbling (size 60 seconds)
group by city_name;
-- get start/end time of window, along with the highest frequency cities
ksql> select timestampToString(WindowStart(), 'HH:mm:ss'),
timestampToString(WindowEnd(), 'HH:mm:ss'), city_name
topk(city_name, 3), count(*) from world
window tumbling (size 1 minute)
group by city_name;
city_name, collect_list(user) from world
window tumbling (size 60 seconds)
group by city_name;
State Stores
For stateful operations, Kafka Streams adopts the concept of State Stores.
- Apply to Windowing, Join and Aggregation concepts
- Adopts RocksDB database per default
- Storage directory defined by
ksql.streams.state.dirproperty. By default, state is stored in the/tmp/kafka-streamsdirectory. In this directory, RocksDB files are created.
Stateful operations generate additional overhead (IO processing), so they will perform worse than stateless operations.
Functions
User Defined Functions
There are two types of user defined functions:
- UDF: User Defined Functions: stateless scalar functions (one input and one output)
- UDAF: User Defined Aggregated Functions: stateful aggregated functions (one or more inputs, and one output)
Those functions are implemented in isolation, in a very simple Java code, and deployed as a separated jar, in a particular directory called ext. This directory must be created inside the base directory defined by the ksql.extension.dir property:
ksql> list properties; -- check for 'ksql.extension.dir' prop value
After put the jar in this directory, it is necessary to restart ksqlDB in order to changes to take effect.
In order to view the installed functions and get details of them, one can just type:
ksql> list functions;
ksql> describe function <function_name>;
And in order to use the function, one can just declare it in a select statement:
ksql> select my_own_function('some value') from ...;
More detailed information about UDF creation can be found on this Confluent article.
Geospatial
This is a scalar function, able to get the distance between two coordinates.
geo_distance(lat1, lon1, lat2, lon2, 'km')
KSQL Deployment Choices
There are two main ways to deploy ksqlDB:
- Interactive Mode: Using CLI, Confluence Control Center or REST API
- Headless Mode: By executing a specific script:
[confluent $] ./bin/ksql-server-start ./etc/ksqldb/ksql-server.properties \
--queries-files=/path/to/query/file.ksql
In headless mode, command prompt do not work. In order to check for results, the related topic must be consumed.
Query Explain Plan
This is a similar concept to relational databases. First, it is necessary to get the execution ID of a query:
ksql> show queries;
Now, one can show the execution plan for this particular query:
ksql> explain <query id>;
The Query Execution Plan will be shown, along with runtime information, metrics, and query topology (the same from Kafka Streams).
Scaling, HA and Load Balancing
The ksqlDB application run on top of Kafka Streams mechanism. So, in order to scale, it is only required to add more instances.
- All instances must have the same properties values in order to form a ksqlDB cluster and share the workload:
bootstrap.serverandksql.service.id.- By default,
ksql.service.id=default_.
- By default,
- In case of failure, other instances take charge.
In regards of High Availability, ksqlDB cluster continues to process data seamlessly with both entrance and leaving of instances in the cluster. If there are no instances running during a period of time and then the first instance starts to work again, processing will restart from the latest read message (no data is lost).
Using Kafka Connect with ksqlDB
ksqlDB is able to register both Kafka Connect sources and sinks.
Let’s consider a Postgres table:
> CREATE TABLE carusers (username VARCHAR, ref SERIAL PRIMARY KEY);
> INSERT INTO carusers VALUES ('Maria');
The first step here is to register a Kafka JDBC Source Connector. This can be done by using ksqlDB CLI:
ksql> create source connector "postgres-jdbc-source"
with ("connector.class='io.confluent.connect.jdbc.JdbcSourceConnector'",
"connection.url='jdbc:postgresql://postgres:5432/postgres'",
"mode='incrementing'", "incrementing.column.name='ref'",
"table.whitelist='carusers'", "connection.password='password'",
"connection.user='postgres'", "topic.prefix='db-'", "key='username'")
A db-carusers topic will be created and Kafka Connect Source will send data to it at each change in Postgres table.
This entries can be monitored in ksqlDB, as previously seen in this post:
ksql> print 'db-carusers' from beginning;
Data Encodings
ksqlDB supports three serialization mechanisms: CSV, AVRO and JSON.
JSON and CSV
If one of these value formats are defined in the Stream and data came to the stream in different formats, no message will arrive at the stream, due to the existing validation mechanism. The error will be available at the log files, that can be configured in the etc/ksqldb/log4j.properties file.
AVRO
In order to Avro to work with ksqlDB, Confluent Schema Registry must be running. To use this data encoding mechanism, it is just necessary to specify value_format='AVRO' in the stream creation.
Avro has a schema mechanism that allows data to be properly validated. So, when trying to generate an invalid value, the error is identified at the producer side of Kafka, due to the ability to validate data in Avro against its schema before sending.
Data Structures: Nested JSON
ksqlDB supports nested and flat data structures. For nested structures ksqlDB adopts the data type STRUCT, as below:
ksql> create stream weather(city STRUCT <name varchar, country varchar,
latitude double, longitude double>, description varchar)
with (kafka_topic='weather', value_format='JSON');
ksql> select city->name as city_name, city->country as city_country from
weather emit changes;