Kafka Core Concepts
Review of the core concepts in Apache Kafka.
Kafka is a distributed, resilient, fault tolerant streaming platform that works with high data throughput. In this page, the main concepts of Kafka technology will be covered.
- How it starts
- The ideia behind Kafka
- Kafka main characteristics
- Zookeeper
- Brokers
- Topics and Partitions in a Single Broker
- Topics and Partitions in a Cluster
- Advantages of Kafka Cluster
- Replication of Partitions
- Topics: Partitions and Segments
- CLI: important commands to know
- References
How it starts
This section is heavily based on the O’Reilly free book ‘Kafka: The Definitive Guide’, that can be downloaded at https://www.confluent.io/resources/kafka-the-definitive-guide/.
At first, let’s consider a simple messaging system for metrics gathering.
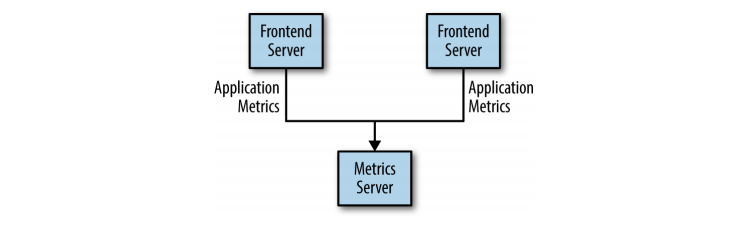
Figure: Simple Publisher Messaging System (from ‘Kafka: The Definitive Guide’ Book)
This is a simple solution for generic metrics. However, over time, this solution increases as new requirements related to metrics arrive. New kinds of metrics arise, along with new systems to consume those messages.
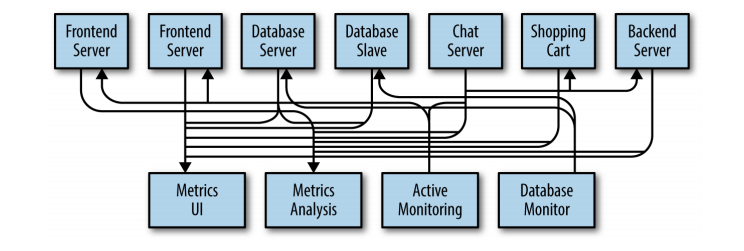
Figure: The Metrics Messaging System evolves (from ‘Kafka: The Definitive Guide’ Book)
Some technical debt is created now, because of all of those integrations out of control. In order to organize all this, you can consider to centralize these metrics in one central application.
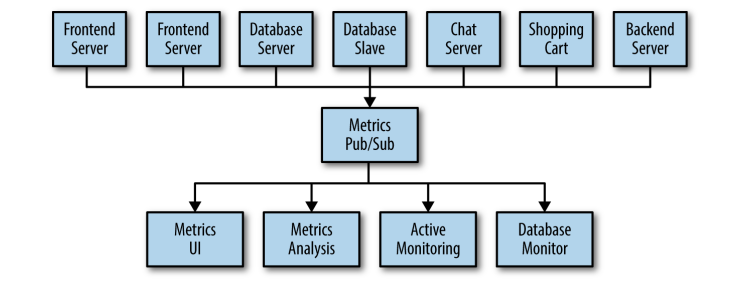
Figure: Central System for Metrics Management (from ‘Kafka: The Definitive Guide’ Book)
Great. The architecture design is much better now. But imagine that, at the same time, different initiatives are arising in your company, for different kinds of messaging integration needs (instead of metrics, there is also demand for logging, tracking, and so on).
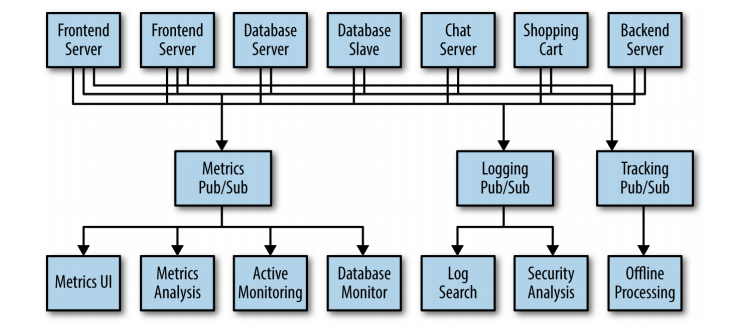
Figure: Multiple Publish/Subscribe Systems (from ‘Kafka: The Definitive Guide’ Book)
There is a lot a duplication in this architecture evolution, since this three pub/sub systems have a lot of characteristics and features in common.
The ideia behind Kafka
Apache Kafka is a system designed to solve this problem. Instead of having different systems that handle messaging problems in isolation (with their own bugs, scopes, schedules and so on), it would be better to have a single centralized system that allows you to publish generic data, that can be used by any sorts of clients. In that way, your team do not have to worry about maintain a pub/sub messaging system for themselves - they can just use a generic system, and focus on the specific problems of the team.
In Kafka model, different systems can produce data and consume data using different kinds of technologies:
- Protocols: TCP, FTP, JDBC, REST, HTTP, etc
- Data Format: JSON, XML, CSV, Binary
- Data Schema
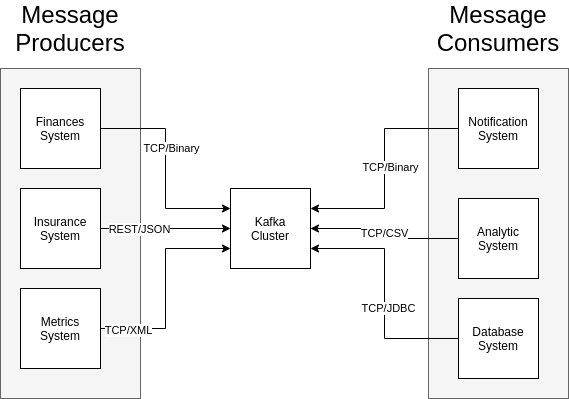
Figure: System can produce and consume data to and from Kafka.
Basic Terminology: Zookeeper, Brokers, Producers and Consumers
As presented in the previous figure, Kafka have some particular names for its main architecture components:
- Broker: is the same of a Kafka Server. A Kafka Cluster is a group of brokers;
- When connected to a Broker in a Cluster, you’re connected to all Brokers in that cluster
- Producer: is the client that produces data to Kafka Broker;
- Consumer: is the client that consumes data from Kafka Broker;
There is also Zookeeper, which is mandatory for Kafka, and responsible to manage metadata of the entire Kafka Cluster.
The following figure explains how the iteration between those components occur, in a nutshell:
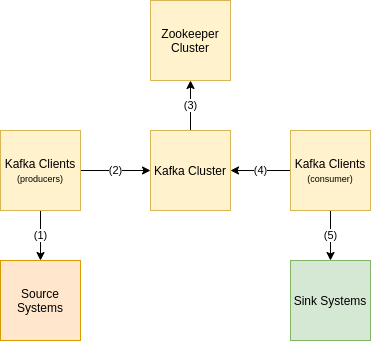
Figure: Kafka Roundup.
- In (1), a Kafka Producer reads data from a generic source system (for instance, an REST API)
- In (2), a Kafka Producer send data previously read to Kafka Cluster
- In (3), Kafka Brokers interact with Zookeeper Cluster for metadata
- In (4), A Kafka Consumer reads data from Kafka (related to the API previously sent by Kafka Producer)
- In (5), a Kafka Consumer sends read data to a sink system (for instance, Twitter)
Kafka main characteristics
- Distributed: Kafka works with several servers (or “brokers”), that form a cluster
- Resilient and Fault Tolerant: If one broker fails, others can detected and divide the extra load
- Scale: Kafka can scale horizontally to 100+ brokers
- High Throughtput: can reach mllions of messages per second
- Low Latency: can handle data traffic in less than 10 ms (realtime)
Throughtput and Latency
It is important to define the concepts of throughtput and latency. These are complimentary concepts, and they are key in Kafka:
- Throughtput: Define how many messages can be processed in a specific amount of time. For instance: the broker can deliver 10,000 messages per second
- Latency: Define how much time does it take for a single message to be processed. For instance: a message can be produced and acknowledged in 5 milisseconds.
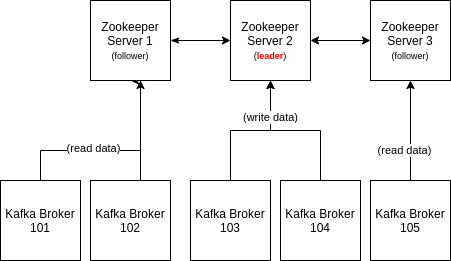
Zookeeper
Zookeeper is a essencial key in Kafka. Some of its characteristics:
- Stores data about Partition Leaders, Replicas and ISRs
- Store general information about changes in the cluster: for instance: new topics, new dead brokers, new recovered brokers, deleted topics, etc.
- Stores ACLs
Since Kafka do not work without Zookeeper, it is important to understand it better.
Zookeeper Mechanism
- Zookeeper always work with a even number of servers (3, 5, 7, etc).
- Each Zookeeper Server in a cluster can be a Leader or a Follower:
- Leader: handle writings
- Followers: handle readings
- In a Kafka Cluster, only brokers talk to Zookeeper. Kafka clients do not.
Figure: Zookeeper interaction with Kafka Brokers in a Kafka Cluster.
Brokers
Identity and naming
Each broker in Kafka is called a “Bootstrap Server”. A broker have an Id (integer and arbitrary number), that identifies it internally in the cluster.
Broker Discovery
The mechanism of Broker Discovery is explained as follows:
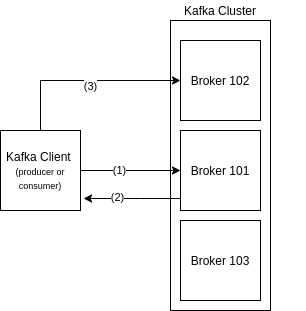
Figure: Interaction between client and server.
- In (1), client connects to a bootstrap server 101 and asks for metadata.
When connecting to a cluster, it is better to inform a list of brokers instead of a single broker, because one particular broker may be down and you can’t connect in the cluster if you are trying to connect in that particular dead one.
- In (2), server responds with metadata to the client. This data actually lives in Zookeeper, and kafka Broker is responsible to get it and deliver to the clients;
A Kafka client never talks to Zookeeper directly; only brokers do (since Kafka 0.10).
- In (3), client knows where to go to get the required data. It finds its partition of interest in metadata. It discovers in which Broker the Partition Leader of that partition are, and then connects to that Broker (for instance, Broker 102 in the figure).
It is not necessary to configure or code anything in Kafka Clients for this Broker Discovery to work as mentioned. This mechanism happens internally in Kafka Clients, by design.
Number of Kafka Brokers per Cluster
A single cluster can have three brokers, and scale to hundreds.
Topics and Partitions in a Single Broker
A topic is defined as a stream of data. Internally, each topic is divided in N partitions.
A partition is a ordered log of messages. It is called ‘ordered’ because messages are stored in partitions in the order they arrive. It is called a ‘log’ becauses data is always appended to the end and never changed - like a log file. Each message in a partition have an positional ID, starting at zero, which is called offset.
Each partition can handle a throughput of MBytes/sec (depending on cluster setup, latency, etc)
This is how this concept looks like in a single broker:
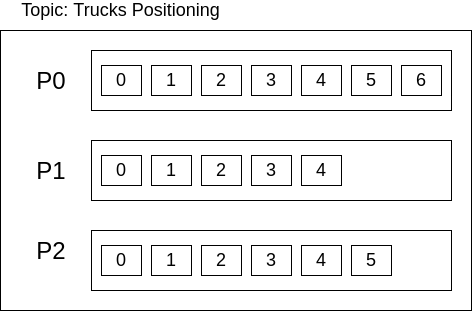
Figure: Topics, Partitions and Offsets in a Single Broker.
Each topic represents a concept of data. It can be something like metrics of some sort, website activity tracking, event sourcing, log aggregation, etc. There are a lot of use cases that can be represented in a topic.
Number of Partitions: Pros and Cons
In the previous example, a topic have three partitions. But it can have one single partition, or dozens of partitions. So, it is important to understand how many partitions a topic must have - and why.
The number of partitions in a topic is important for throughput. With only one partition, you cannot use multiple threads to read the data - if you do, you’ll read repetitions. But if you split your 10,000 messages in three partitions, for instance, then you could read/write data in parallel (in three clients in a consumer group), and this will improve your throughput. In addition to that, Kafka ensures that only one consumer (from a consumer group) can read a partition at a time (avoiding duplication reads).
This approach (performance enhancement when reading data “splitted” in different partitions) will not work if your data must be read in the same particular order that was written. Check the next section below in this page (‘Distributions of Messages in a Topic’) for further info.
More partitions also ensures the ability to leverage to more brokers in a cluster.
However, it also brings the following issues to deal with:
- More elections to be done by Zookeeper
- More open files in Kafka
Guidelines for the Magic Number of Partitions
The following are some guidelines that help when choosing the number of partitions in a topic:
- What is the expected throughput for a topic?
- 1GB/sec is very different that 10KB/sec
- What is the maximum throughput expected to be consumed by a single partition?
- It is important to know your consumer throughput. Considering that your consumer is bounded to a single partition, and if you know that your consumer will write Kafka data into database and the database throughput have a maximum of 50MB/s for a single thread to write into it, it should be OK to consider that you are limited a 50MB/s for that partition.
- What is the maximum throughput expected to be produced to a single partition?
- Same rationale as above. However, producers are typically faster than consumers, so it is less critical to analyze this
- Message keys are being used?
- If so, it will be a problem if it should be required to add partitions later (because of the way messages keys are distributed in partitions). The ideal is to plan considering increase for the future (next two years, for instance), instead of to plan for the current scenario
- Avoid overestimate, because partitions cost memory and I/O, perform replication and will increase time for leader elections in case of relabancing
In a topic, partitions can be added, but cannot be reduced.
One metric: Calculation Based on Expected Topic’s Throughtput
With that in mind, consider the formula:
nP = Tt / Ct
where: nP = number of partitions; Tt = Target throughtput of topic; Ct = consumer throughput
For instance, if Tt = 1GB/s and Ct = 50MB/s, the formula recommends to adopt 20 partitions (1000M/50M). That way, I need to have 20 consumers reading for that topic (one consumer per partition) in order to achieve 1Gb/s.
Other metric: Experience (from Maarek’s course)
- Small Cluster (< 6 brokers):
# of partitions = 2x # of brokers - Big Cluster (> 12 brokers):
# of partitions = 1x # of brokers
The throughtput can also be considered:
- Throughtput for Consumers: consider the number of consumers that will run in parallel in peak time (one consumer reading one partition is the ideal scenario)
- Throughtput for Producers: it must also be considered. Increase the number of topics if the thoughtput is too high or expected to increase in the next couple of years
These are only guidelines, and not rules of thumb. It is still also required to perform tests, because each cluster behaves differently (due to network issues, configuration issues, firewalls, etc)
Distributions of Messages in a Topic
When data arrives to a topic that have more than one partition, Kafka must decide in which partition to store it. The data can be write randomly in a partition of the topic (what is called “round robin”) or the same data can always go to the same partition.
Each message in Kafka can have the basic structure:
valueorkeyandvalue
If the message only have value, it will be written to any of the partitions of the topic, according to round robin algorithm. But, if a key is also informed, the algorithm MurmurHash2 will be applied on the key to decide to which partition the message must be stored.
So, if 10 different messages arrive in Kafka:
- with the same key: they will all be stored in the same topic, in the order that they arrived. This is important if the requirement of the topic is to store messages that must be later consumed in the same order that they arrived (because the consumer of data can just read all data from a particular partition, in order). The reading is performed the same way, by using message key and MurmurHash2 algorithm.
- without any key: Kafka will use round robin to distribute these 10 messages through all of the partitions of the topic. In a topic with three partitions, maybe 3 messages go to Partition0, another 3 Message to Partition1 and 4 messages go to Partition2.
- with a mix (3 messages with same key, 7 messages without key): the 7 messages without key will be distributed randomly, and the remaining 3 messages with the same key will go to the same partition. Each message is independent from the others.
- This approach is not a good idea: if your topic receives messages with and without key, you can have side effects - for instance, you may expect that only messages with key “truckID123” will be write to a particular partition (“all geolocation messages from truck 123”), but when you read that partition, some messages different that of this particular truck (for any arbitrary truck) also shows up. That is because Kafka will distribute messages without key to any of the topics of the partition - including those that are also being used to store data of particular key.
- The best approach is to decide, at topic level, if message key will be adopted or not, and be consistent with it. Just do, or do not, as Yoda teached us.

Figure: In a topic, use message keys or do not use message keys.
Some notes regarding the logic of message distribution in partitions:
- The MurmurHash2 algorithm is based on the number of partitions of a topic. So, if it’s important to maintain order (and, hence, you’re using Message Keys for that), make sure that the number of partitions of your topic do not change. If they change, you may have unexpected behaviors.
- It is also possible to overwrite the algorithm behavior (change MurmurHash2 for something else), by overwriting the Kafka
DefaultPartitionerclass. - You can also to explicit define which data goes to which partition of a topic, when writing the producer client. You have to use the API for that (
ProducerRecordclass).
Topics and Partitions in a Cluster
If you have a single broken, all your data and availability relies on this particular broker. This is not a good idea, because you have no scalability and no fault tolerance. If this server goes down, you application is gone. If the disk corrupts, it is also gone. A single broker could be nice for development purposes, but a Kafka architecture must always be deployed as a cluster.
Advantages of Kafka Cluster
- No data is lost: The data is replicated through brokers per design
- Fault tolerance and availability: All brokers serve data as one. If one goes down, the others will organize themselves to respond in its behalf. Kafka can rebalance and redistribute the load with no harm.
Replication of Partitions
In a Kafka Cluster, data can be replicated between brokers. This is one of the most powerful concepts in Kafka.
Let’s consider the previous mentioned Trucks Positioning Topic:
Figure: Topics, Partitions and Offsets In a Single Broker - revisited.
In a single broker, if it goes down or the disk is corrupted, this topic will be gone. But let’s consider this same topic using replication factor of two with three brokers:
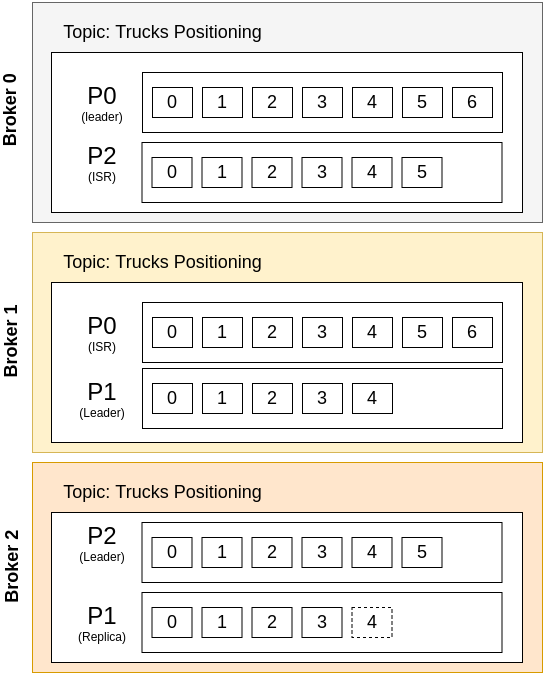
Figure: Replication of Data of Topic between three Brokers in a Cluster.
There are a lot of information in this figure.
The Same Topic exists in Multiple Brokers
Because of the Replication Factor of 2, each partition of the topic “Trucks Positioning” exists in 2 different Brokers of 3 available in the cluster (ids: 0, 1 and 2).
So, it is correct to say that each topic can exist in different brokers, but the data of a topic is not entirely in a single broker. For instance, the partition P2 is available only on Brokers 0 and 2 - but not in Broker 1.
If you want all the partitions of a topic to exist in all of the brokers of a cluster, this can be achieve by setting the replication factor number equal to the number of partitions - in this case, 3. But this is not a good rule to follow, because, if you cluster have 100 brokers, you do not necessarity wanna have 100 partitions for a single topic. More on that in the next sections.
It is not possible to have a Replication Factor number higher than the number of brokers - and there will always be a single replication factor, as a minimum. For instance, consider four brokers: the replication factor must be >= 1 and <= 4. And consider a single broker: the same rule applies (replication factor >= 1 and <= 1 => must be always 1). If you try to create a topic with the wrong number of replication factor, Kafka will throw a org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: ? larger than available brokers: ?..
Leader Partition, Replicas and ISR
Kafka defines each partition in a topic as a Leader Partition, Replica Partition or ISR (In-Sync Replica) Partition.
A Leader Partition is the entry point for all the clients. When some client have to read data from partition P1, for instance, the following happens, in a nutshell:
- Kafka Client asks for any kafka Broker for the metadata related to the partitions of a topic
- Kafka Broker will get metadata from Zookeeper (the metadata from partitions in a topic is stored in Zookeeper)
- Kafka Broker will deliver the updated metadata info to the client
- Kafka Client will search in metadata for the Broker who is the Leader of Partition
P1- in this case, it is Broker 1 - Kafka Client will ask to Broker
1for data in the partitionP1
For a particular partition, only one Broker can be its Leader at a time. There is no scenario where a partition have more than one Leader.
When some client send data to be written to Kafka, a Partition Leader gets data and is responsible to deliver to one of the Replicas (itself or other replicas). When that particular data is in-sync, the partition is called a In-Sync Replica.
A Replica Partition is just a replica of data. This is a copy of a Leader Partition data, and this partition will not be directly called by any clients - that is a characteristic only for the Leader. A Replica partition may or may not be syncronized (or in-sync) with the Leader Partition.
- In Figure above, the Partition
P1in Broker2is a Replica which is not in sync. The message withoffsetId 4are still not synchronized.
A In-Sync Replica is a Replica Partition that is definitely in sync with the Leader Partition. In the Figure above, the Partitions P2 in Broker 0 and P0 in Broker 1 are in sync.
This information (partition, leaders, replicas and isr) can be seen when we describe a topic, as below:
ubuntu@ip-x:~$ ./kafka/bin/kafka-topics.sh --zookeeper zookeeper1:2181/kafka
--topic teste --describe
Topic: teste PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: teste Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: teste Partition: 1 Leader: 1 Replicas: 1,2 Isr: 2,1
Topic: teste Partition: 2 Leader: 2 Replicas: 0,2 Isr: 0,2
Some notes on this regard:
- A Partition Leader is also a Replica, but with a more important function, and every topic has one Partition Leader. So, in a topic of three partitions and replication factor of three (which means three brokers), for instance, there will be nine replicas, and three of those replicas (one in each broker) will also be Leaders.
- A particular partition can be Leader in a Broker and a Replica in another Broker. That is OK by design.
- The sync mechanism takes some time, but is something that Kafka does internally - a Replica Partition will always became in-sync, but may take some time. More on that on Producers and Consumers section.
What Happens if a Broker Fails? Rebalance and Replication of Data
Kafka is able to detect that a Broker in a Cluster is no longer available, because Kafka brokers exchange health check messages between each other.
When this happens, Kafka will perform a Leader Election considering the remainder brokers. For each partition that was a Leader in the missing broker, Kafka will elect a new Leader of that partition in a different (live) broker. That way, partitions are still available to the clients (since only leaders interact with client, as previous mentioned).
For instance, considering the Figure above, let’s assume that Broker 1 is down. The result can be seen in Figure below (with side effects in green):
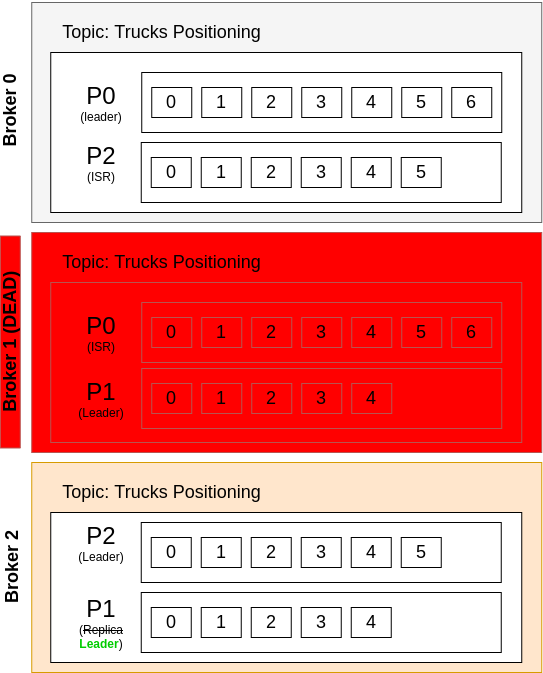
Figure: Replication of data when a broker goes down.
In summary, what happens is the following:
- After some time, Kafka Brokers
0and2realize that Broker1is down and, therefore, PartitionP1no longer a has a Leader - A new Leader Election occur for
P1. SinceP1only exists in Broker2(and not in Broker0), the elected Broker Leader forP1is now Broker2. - In this scenario, the Partition
P2still maintain in-sync replica of two (because exists in Broker0and Broker2), but PartitionsP0andP1only exists in a single Broker (since Broker1is dead), and for those, the in-sync replicas are now only one. Kafka will not rebalance data in order to “force” anything - it will wait for Broker1to recover and will remain with2replicas and1in sync replica for these.
This can be seen when describing the same topic again:
ubuntu@ip-x:~$ ./kafka/bin/kafka-topics.sh --zookeeper zookeeper1:2181/kafka
--topic teste --describe
Topic: teste PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: teste Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0
Topic: teste Partition: 1 Leader: 2 Replicas: 1,2 Isr: 2
Topic: teste Partition: 2 Leader: 2 Replicas: 0,2 Isr: 0,2
The Leaders have changed to reference only alive brokers (0 and 2), the replicas remain the same, and the ISRs references only alive brokers as well.
But this still works - meaning that Kafka can respond to the clients properly, because we have a Leader for each partition of a topic. But what if both Brokers 1 and 2 both die?
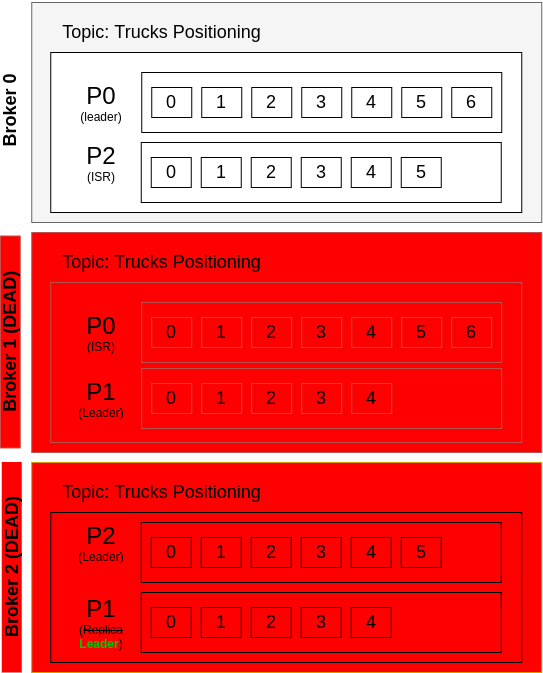
Figure: Two goes down - only one broker left.
In that case, the Partition P1 is not available anymore, anywhere. Since there are no Leader for Partition P1 anymore, producers and consumers will crash when trying to send and get data to the topic.
When creating a topic, the number of active brokers must be equal or higher than the replication factor number (for instance, if replication factor is 2, then you must have at least two brokers). But if one server goes down after a topic creation, it will still be working if there is a Leader for each partition (even if the number of brokers is less than replication factor). The replicas will remain the same - the ISRs are the ones that will be updated to the new situation.
ubuntu@ip-x:~$ ./kafka/bin/kafka-topics.sh --zookeeper zookeeper1:2181/kafka
--topic teste --describe
Topic: teste PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: teste Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0
Topic: teste Partition: 1 Leader: none Replicas: 1,2 Isr: 2
Topic: teste Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2
There is no Leader for one partition, so this topic is not available to clients.
Rules to elect a Leader
There are two behavious that Kafka can assume:
- A Leader will be a in-sync replica (which means that it has the most updated data). That is the default in Kafka, and ensures consistency over availability.
- A Leader will be a replica (which means that it does not have the most updated data). This behavior will ensure availability over consistency.
Unclear Leader Election
If the ISRs are all dead but there are some non-ISRs up, you can wait for the ISRs to get back to life or to start using non-ISRs partitions.
Using non-ISRs is a highly dangerous approach. The availability will be increased, but messages from unavailable ISRs (at the moment) will be discarded. The use cases is related to it are about metrics, logs, and any sort of data that may be lost without further issues.
If it is truly required, one must set the following broker-level property:
unclean.leader.election.enable=true
The Ideal Replication Factor Number for a Topic
Usually, the replication factor should be a number between 2 and 4. It is better to set it as 3 for start.
Considering a replication factor of N, Kafka Clients can tolerate N-1 dead brokers. A replication factor of 3 seems good.
With replicationFactor=3 => N-1=2 brokers can goes down
- 1 server may goes down for maintenance
- 1 server may goes down for unexpected reasons (general errors)
And the topic still responds property to the clients.
It is not a good idea to change a replication factor after being defined. This may overload the broker, affecting performance.
When using a high replication factor number, some issues may be considered:
- The replication between brokers will increase, and so the latency (if
acks=all) - The disk usage will increase dramatically
If the number of replication factor=3 is still an issue (because of disk usage and latency), consider improve the broker resources/network instead of reduce the replication factor.
Try Not to Change Replication Factor and Number of Partitions
It is important to define those attributes right in the first time. To change replication factor may affect performance, and to change the number of partitions when using key will create unexpected behaviors.
Topics: Partitions and Segments
Main concepts
- Each topic has one or more partitions
- Each partition is represented as a directory in a file system
- The name of directory is:
<topic-name>-<partition number> - For instance:
sometopic-1,sometopic-2, etc
- The name of directory is:
- Each partition is make of segments
- Each segment is composed of few files in this particular directory
- Only the last segment is the active (where data is written)
- Previous segments are just for reading of data
Properties
log.segment.bytes:the maximum size of a segment (file) in bytes (default: 1GB)
Segments: Files in a Topic-Partition Directory
Each segment is represented as files in a partition directory:
ubuntu@ip:/data/kafka/teste-2$ ls -l
total 20
-rw-r--r-- 1 root root 10485760 Oct 9 08:16 00000000000000000000.index
-rw-r--r-- 1 root root 153 Oct 8 10:21 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Oct 9 08:16 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10 Oct 6 10:29 00000000000000000001.snapshot
-rw-r--r-- 1 root root 10 Oct 8 10:36 00000000000000000003.snapshot
-rw-r--r-- 1 root root 14 Oct 9 08:16 leader-epoch-checkpoint
The directory teste-2 means that the files are related to topic teste, partition 2. These files represent segments, with specific characteristics according to its extensions:
.log: these are the files where messages are stored.index: control the index of segments (as offsets); maps messages positions related to the the log file. This file have a fixed size of 10MB. This file is important because the log files are huge (default 1GB), and and index file (that stores the offset and physical position of data from a log file) gives efficiency when getting messages..timeindex: control the index of segments in timestamp; Kafka uses it to find messages by timestamp. This file have a fixed size of 10MB..snapshot: ?
And the files adopt the following convention:
0000000000000000000N.[extension]
The file name (prefix) have twenty numbers. The N is the number of the first offset of that segment.
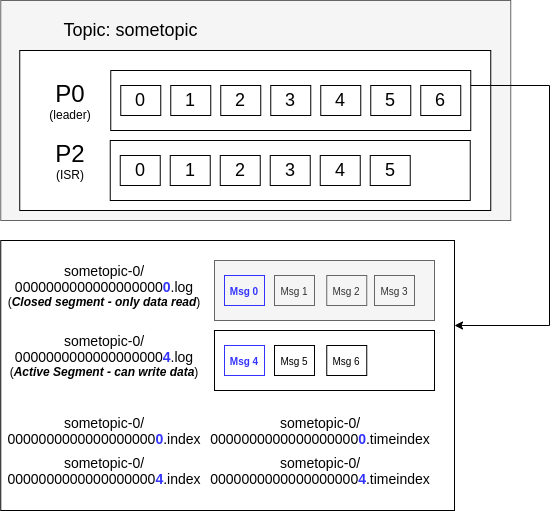
Figure: Kafka Internals: files
Leader-epoch-checkpoint file
And there is also a leader-epoch-checkpoint file. Describe it better.
Checking for log contents
The log file is a binary one. In order to check its content, it is necessary to run a Kafka class:
$ ~/kafka/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration \
--print-data-log --files 00000000000000000000.log
or
$ ~/kafka/bin/kafka-dump-log.sh --deep-iteration --print-data-log \
--files 00000000000000000000.log
The output is below presented. Important data displayed are: creation time, key and value sizes, and message payload.
Dumping 00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1
producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 10
isTransactional: false isControl: false position: 0
CreateTime: 1601977627886 size: 69 magic: 2 compresscodec:
NONE crc: 2885673363 isvalid: true
| offset: 0 CreateTime: 1601977627886 keysize: -1 valuesize: 1 sequence: -1
headerKeys: [] payload: a
baseOffset: 1 lastOffset: 2 count: 2 baseSequence: -1 lastSequence: -1
producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 18
isTransactional: false isControl: false position: 69
CreateTime: 1602152511818 size: 84 magic: 2 compresscodec: NONE
crc: 3265130193 isvalid: true
| offset: 1 CreateTime: 1602152511139 keysize: -1 valuesize: 4 sequence: -1
headerKeys: [] payload: java
| offset: 2 CreateTime: 1602152511818 keysize: -1 valuesize: 4 sequence: -1
headerKeys: [] payload: mano
Log Cleanup Policies
Log cleanup is the cleaning of data, that can happen according to policies.
log.cleanup.policy=delete: Kafka default for user topics
- Exclusion happens based on data time. Property:
log.retention.hours(default: 168 hours = 1 week). Lower number means less data is saved (if the consumers stay down for longer, the will lose data); higher number means more disk space, but more ability to execute replay and less change for dead consumers to lose data when they get back to live - Exclusion happens based on max log size. Property:
log.retention.bytes(default: -1 = infinite)
log.cleanup.policy=compact: Kafka default for “–consumer-offsets” topic
- Exclusion based on message keys. It will erase message with same key from closed segments
- Retention time and space: infinite
Two very common use cases are:
- One week of retention: the default.
log.retention.hours=168andlog.retention.bytes=-1 - 500MB per partition, and time doesn’t matter:
log.retention.hours=1000000andlog.retention.bytes=524288000
How Often Log Cleanup Occur?
The checking occur according to the property log.cleaner.backoff.ms (default: 15s).
It happens in the closed partition segments. So, more segments means more compaction to be executed. Since this procedure consumes CPU and memory, it is important to consider the proper size for segments.
Segments’ Size Considerations
Small segments means:
- more segments per partition
- log compaction happens more frequently
- Kafka must keep more open files (error: too many open files)
So, in order to define the segment size, one must consider throughput:
- 1GB/day: let default size
- 1GB/week: should consider size reduction
Log Cleanup: Compaction
The idea in log compaction is to keep only the last update of a key in a log, and discard the others. It is very useful when the only required data is the latest version of a data, and the history is not important. This will save a lot of disk space.
- The tail of the log (active segment) is not affected. Only the closed segments will be compacted
- The offsets are immutable. A message will be deleted but the remainder messages will keey the same offset id. Hence, it is natural to have skipped offsets after compaction.
- The order of the messages is never changed, even after compaction
- Deleted messages can still be viewed by the consumers for a period of time, according to property
delete.retention.ms(default: 24 hours).
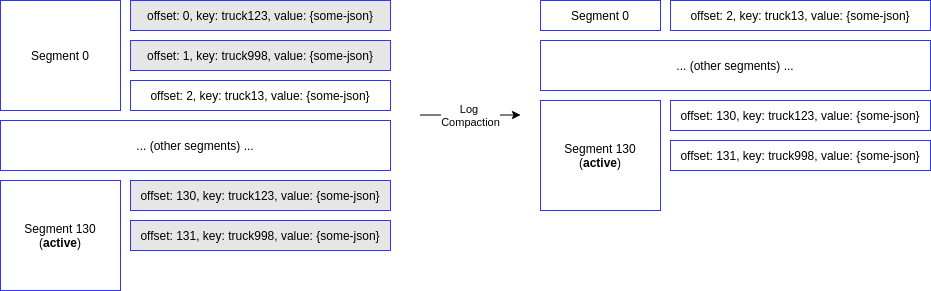
Figure: Segment 0 is compacted, since there are updated message with the same key
In order to configure a new topic to check log cleanup compaction in practice, it must be created with specific properties (and values for testing):
$ ./kafka-topics.sh --bootstrap-server kafka1:9092 --create --topic
truck-position --partitions 1 --replication-factor 1
--config cleanup.policy=compact --config min.cleanable.dirty.ratio=0.001
--config segment.ms=5000
Analyzing these properties:
min.cleanable.dirty.rationhave a very small number, which ensures that log compaction will happen all the timesegment.msensures that a new segment will be created every 5 seconds- only one partition make tests easier to verify
CLI: important commands to know
Topic Creation
# create locally in a single broker
$ ./kafka-topics.sh --zookeeper localhost:2181 --create --topic sometopic
--partitions 2 --replication-factor 1
# in a cluster of zookeeper with a single kafka broker
$ ./kafka-topics.sh --zookeeper zookeeper1,zookeeper2,zookeeper3:2181/kafka
--create --topic sometopic --partitions 2 --replication-factor 1
# in a cluster of zookeeper with a kafka cluster of 3 (repl. factor)
$ ./kafka-topics.sh --zookeeper zookeeper1:2181,zookeeper2:2181,
zookeeper3:2181/kafka --create --topic sometopic --partitions 2
--replication-factor 3
# same as above, but port definition can be simplified to the end of servers
$ ./kafka-topics.sh --zookeeper zookeeper1,zookeeper2,zookeeper3:2181/kafka
--create --topic sometopic --partitions 2 --replication-factor 3
# --zookeeper is deprecated since 2.0 - using bootstrap-server instead
# /kafka suffix must not exist (it is only for zookeeper directory path)
# and port definition cannot be simplified (every broker declare its port)
$ ./kafka-topics.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092
--create --topic sometopic --partitions 2 --replication-factor 3
Topic List
$ ./kafka-topics.sh --bootstrap-server kafka1:9092,kafka2:9092 --list
# show the amount of messages per partition
$ ./kafka-run-class.sh kafka.tools.GetOffsetShell \
--broker-list kafka1:9092 --topic sometopic
Topic Describing
$ ./kafka-topics.sh --zookeeper zookeeper1,zookeeper2,zookeeper3:2181/kafka
--topic sometopic --describe
Topic Exclusion
$ ./kafka-topics.sh --zookeeper zookeeper1,zookeeper2,zookeeper3:2181/kafka
--topic sometopic --delete
Topic Configuration
# list topic configuration properties (deprecated)
$ ./kafka-configs.sh --zookeeper zookeeper1,zookeeper2,zookeeper3:2181/kafka
--entity-type topics --entity-name sometopic --describe
# adding a partition (the number must be higher than actual # of partitions)
$ ./kafka-topics.sh --bootstrap-server kafka1:9092 --alter --topic sometopic
--partitions 3
# adding a property configuration
$ ./kafka-configs.sh --zookeeper kafka1:2181 --entity-type topics
--entity-name sometopic --add-config min.insync.replicas=2 --alter
# removing a property configuration
$ ./kafka-configs.sh --zookeeper zookeeper1:2181/kafka --topic sometopic
--delete-config min.insync.replicas --alter
Producing Messages
# in a single broker
$ ./kafka-console-producer.sh --broker-list localhost:9092 --topic sometopic
# in a cluster
$ ./kafka-console-producer.sh --broker-list kafka1:9092,kafka2:9092,kafka3:9092
--topic sometopic
# with key
$ ./kafka-console-producer.sh --broker-list kafka1:9092,kafka2:9092,kafka3:9092
--topic sometopic --property parse.key=true --property key.separator=,
Consuming Messages
# in a single broker (from the end of a topic - default)
$ ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sometopic
# in a cluster (from the end of a topic - default)
$ ./kafka-console-consumer.sh --bootstrap-server kafka1:9092,kafka2:9092,
kafka3:9092 --topic sometopic
# in a cluster (from the beginning of a topic)
$ ./kafka-console-consumer.sh --bootstrap-server kafka1:9092,kafka2:9092,
kafka3:9092 --topic sometopic --from-beginning
# with consumer group
$ ./kafka-console-consumer.sh --bootstrap-server kafka1:9092,kafka2:9092,
kafka3:9092 --topic sometopic --group sometopic-g1 --from-beginning
# with key
$ ./kafka-console-consumer.sh --bootstrap-server kafka1:9092,kafka2:9092,
kafka3:9092 --topic sometopic --from-beginning --property print.key=true
--property key.separator=,
Managing Consumer Groups
# listing
$ ./kafka-consumer-groups.sh --bootstrap-server kafka1:9092,kafka2:9092,
kafka3:9092 --list
# describing topic info (get offset data)
$ ./kafka-consumer-groups.sh --bootstrap-server kafka1:9092,kafka2:9092,
kafka3:9092 --group sometopic-g1 --describe
# reset offset to earliest (must be inative - no consumers using it)
$ ./kafka-consumer-groups.sh --bootstrap-server kafka1:9092,kafka2:9092,
kafka3:9092 --group sometopic-g1 --reset-offsets --to-earliest --execute
--topic sometopic
# reset offset to -2 position (must be inative - no consumers using it)
$ ./kafka-consumer-groups.sh --bootstrap-server kafka1:9092,kafka2:9092,
kafka3:9092 --group sometopic-g1 --reset-offsets --shift-by -2 --execute
--topic sometopic
Reassigning Partitions
$ kafka-reassign-partitions.sh --zookeeper host:2181
--topics-to-move-json-file file.json --generate
$ kafka-reassign-partitions.sh --zookeeper host:2181
--reassignment-json-file file.json --execute
$ kafka-reassign-partitions.sh --zookeeper host:2181
--reassignment-json-file file.json --verify