Kafka Consumer Concepts
Review of the consumer concepts in Apache Kafka.
Kafka is a distributed, resilient, fault tolerant streaming platform that works with high data throughput. In this page, the main concepts of Kafka Consumer technology will be covered.
- What is a Consumer?
- Consumer Group
- What if my consumers are not in a group?
- Consumer Offsets
- Delivery Semantics for Consumers
- Consumer Poll Behavior
- Consumer Offset: Commit Strategies
- Consumer Offset: Reset Behaviors and Data Retention Period
- Replaying Data for Consumers
- Consumer Internal Threads
- Demo Code: Java Consumers
- CLI: important commands to know
- References
What is a Consumer?
- Consumers are Kafka clients, responsible to read data from Kafka Cluster
- They know automatically which Broker to connect to get the data they need, because of the Broker Discovery mechanism, also used in Producers (other type of Kafka clients).
- Consumer know how to recover in case of Cluster failure: Broker Discovery will be applied after the cluster recovers itself.
- Data is read in the order that was written in the partition.
- Consumer read data from different partitions in parallel, without any order between partitions (the concept of order only exists in the messages from the same partition)
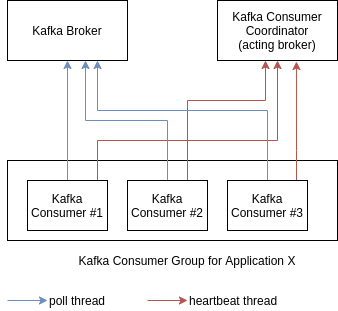
Consumer Group
Kafka group topic consumers in “consumer groups”. This way, each consumer collaborate to read data from a specific partition of a particular topic, improving performance in reading of topic’s data in parallel.
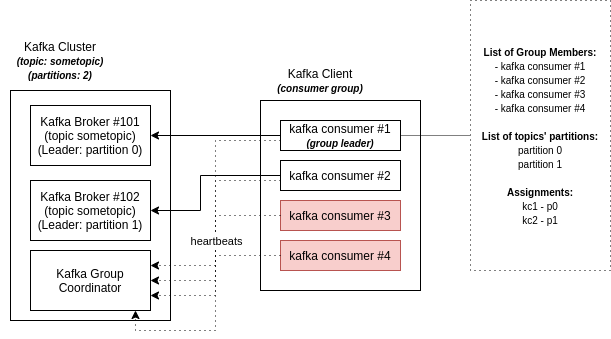
Figure: Kafka Consumer Group mechanism.
- Each consumer group can be seen as a distinct application, responsible to read data from a particular topic (or more than one topic as well)
- If there are more consumers than partitions, some consumers will remain inactive
- This is a internal Kafka Consumer mechanism, and nothing need to be done by programmers in this regard
Kafka defines the relationship between Consumers and Consumer Groups x Partitions using coordinator classes (GroupCoordinator and ConsumerCoordinator):
- When a consumer wants to join a group, it sends a
JoinGrouprequest to to group coordinator. If it is the first to do so, it becames aleaderof that group. A group leader then receives a list of group members (those who send heartbeats to the server and are considered active) and became responsible to assign a subset of partitions to those members (making sure that no partition is assigned to more than one member, while it is still possible for a member to handle more than one partition).- Only the leader has the list of members; each regular member knows nothing about other members in that regard
- This process repeats every time a rebalance happens
In general, the number of consumers in a group must be <= number of partitions. Otherwise, you will remain with inactive consumers - a waste of resources.
In other perspective, when creating partitions for a new topic, one must consider the number of available consumers for that topic. If you only have five available consumers, it should be better to create 5 partitions or less in yout topic in terms of data reading.
What if my consumers are not in a group?
Internally, each consumer is associate to a group in Kafka (even if not directly explicited). If not defined to be part of a group, then your consumers will be part of individual, internal and independent groups.
In this situation, each consumer will consume data independent from the others.
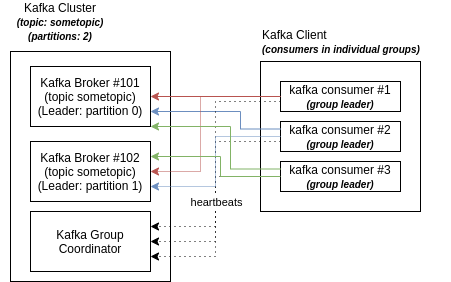
Figure: Kafka Consumer mechanism with implicit, individual groups for each client.
Each consumer read data from all partitions, independent from the others, in duplication - behaving like separate applications.
Consumer Offsets
Kafka consumers read data, and then they have to mark which data was already read (advancing the offset). In order to do it, this index of already read data is saved in a particular topic called __consumer_offsets.
- Actually, when a consumer from a consumer group reads data, it also writes (commit) the offset of read data in the
__consumer_offsetstopic.
Changing offsets of a group
Offsets position can be changed for a group, but all the consumers for that group must be inactive when this happens. To do this offset manual changing, use the kafka-consumer-groups.sh shell (more on that in the next sections).
What about ‘–from-beginning’ parameter?
The parameter --from-beginning is used to consume messages from a particular position in a topic. If used, the data will be read from the oldest offset. If not, data consumption starts from the latest offset.
However, the behavior is different with consumer groups.
If you are using kafka-console-consumer without any explicit group
- with
--from-beginning: it will read data from the beginning of topic - without
--from-beginning: it will read only new data
But, if you’re adopting --group parameter, data will always be read since the last commit offset (and --from-beginning seems not to have the expected behavior).
Delivery Semantics for Consumers
-
at most once: offsets are commited when the message is received by the consumer. If processing of that message goes wrong, the message will be lost (it won’t be read again, since it is already marked as read). Not very adopted.
-
at least once: offsets are commited as soon as data is processed. This is the preferred delivery approach. If there is any issue during processing, the message will be read again. In order to prevent duplicates when reading, the process must be idempotent (read again a message should not affect the system).
-
exactly once: only achieved from Kafka to Kafka workflows (using Kafka Streams, for instance).
Consumer Poll Behavior
Kafka consumer adopts a “poll” model (instead of a push model, which is adopted by many messaging systems). In a poll model, one have better control over consumption, speed and even replay of events.
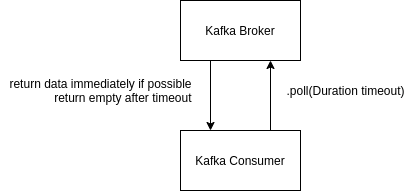
Figure: Kafka Consumer Poll and Broker.
Importart throughput properties
Some important properties that can improve you throughput is below listed. If there is no need to improve throughput, those can remain as defaults:
fetch.min.bytes(default: 1): control how many data can be send in a request. Help improve throughput and reduce number of requests, but decrease latencymax.poll.records(default: 500): control how many messages can be received by poll request. You can increase this number if your messages are small and there is a lot of available RAM. It is also good to monitor how many records are actually being polled by request (if the number is always 500), this property value must be increase to improve throughputmax.partitions.fetch.bytes(default 1MB): maximum data returned per partition. If there is a lot of partition to be read, you’ll have a lot of RAMfetch.max.bytes(default: 50MB): maximum data returned per each fetch request (between multiple partitions). Consumer can perform multiple fetches in parallel for different partitions
Consumer Offset: Commit Strategies
There are some ways to commit offsets in a consumer:
enable.auto.commit=true(default) and processing batches synchronously- by using this property, offsets will be automatically commited in a period of time defined by
auto.commit.interval.ms(default: 5000, or 5s)), every timepoll()method is called - note that if rebalance happens between commit intervals, data will be processed again and may generate duplicates
- by using this property, offsets will be automatically commited in a period of time defined by
while (true) {
List<Records> batch = consumer.poll(Duration.ofMillis(100));
doSomethingSynchronouslyWith(batch);
}
enable.auto.commit=falseand manual, synchronous commit of offsets- by using this property, you control how and when commits are made
- for instance: accumulate messages in a buffer and then save those messages in a database and commit offset.
- commitSync() will retry until finds a non-retriable error
- the problem is that the throughput is affected (since is sync)
while (true) {
batch += consumer.poll(Duration.ofMillis(100));
if (isReady(batch)) {
doSomethingSynchronouslyWith(batch);
consumer.commitSync();
}
}
enable.auto.commit=falseand manual, asynchronous commit of offsets- Now the throughput are improved
- However, there is no retry for async (since the order of commits in different threads are unpredictable). A callback may be used for retries, but the commit order is still an issue.
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s, partition = %s,
offset = %d, customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
}
consumer.commitAsync(new OffsetCommitCallback() {
public void onComplete(Map<TopicPartition,
OffsetAndMetadata> offsets, Exception exception) {
if (e != null)
log.error("Commit failed for offsets {}", offsets, e);
}
});
}
A best approach is to combine sync and async commits:
- a failure with commits without retrying is not a big issue because the next commit will be sucessfull. But if this is the last commit before close the consumer or before rebalance, it is necessary to make sure that will finish correctly
- So, we can use async() for processing during, and use sync() as the last resource just to make sure that will commit at the end, properly, treating failures and retries in that last moment.
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
// perform some action with messages; in this case, let just print those
System.out.printf("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n",
record.topic(), record.partition(),
record.offset(), record.key(), record.value());
}
// commit and forget; there is no retry
// further commits will save properly
consumer.commitAsync();
}
} catch (Exception e) {
log.error("Unexpected error", e);
} finally {
try {
// at the end (closing of consumer or rebalance), this will make sure
// commit (with retry in case of failure) will happen
consumer.commitSync();
} finally {
consumer.close();
}
}
Consumer Offset: Reset Behaviors and Data Retention Period
The property auto.offset.reset defines the behavior of consumer when start reading data from the topic:
earliest: start to read data from the beginning of topiclatest: start to read data from the end of topic
Offset data may also be lost even if earliest is set, because of the log.rentention.hours property. If this property is set for 1 week (default) and the consumer did not run in that period (for instance, it only runs after 10 days), data are no longer there to be consumed.
Replaying Data for Consumers
If is required to replay data, the approach is to reset the offsets for thar particular consumer group.
All consumers must be inactive and the following command must be executed:
$ ./kafka-consumer-group.sh --bootstrap-server kafka1:9092 --group sometopic-g1
--reset-offsets --to-earliest --topic sometopic[:topicNumber] --execute
Consumer Internal Threads
Figure: Kafka Consumer Poll and Heartbeat.
- All consumers in a group talk to a consumer coordinator
- The heartbeat mechanism will detect inactive consumers
- If Kafka do not get a heartbeat signal during a specified period of time, it will consider that consumer inactive and will perform rebalance of partitions to the remainder consumers
- Consumers are encouraged to execute frequent polls and process data rapidly, in order to avoid issues
The main properties in that regard are the following:
session.timeout.ms(default: 10000, or 10s): this is the maximum period of time that the broker will wait for heartbeats from consumer before consider it inactiveheartbeat.interval.ms(default: 3000, or 3s): this is the period of time in which Kafka consumers will send heartbeats to the broker. The general rule of thumb is to set this value as 1/3 ofsession.timeout.msmax.poll.interval.ms(default: 30000, or 5 minutes): This is the maximum interval of time between twopoll()calls, before to declare the consumer as inactive.- This is particularly important to big data applications iteractions, like Spark, where processing could take time
- This property is useful to detect some locked processing in the consumer side. In the case of Big Data, it may be necessary to increase this value or to improve big data processing time.
Demo Code: Java Consumers
The next examples were taken from the excellent Stephane Maarek’s Kafka Course @ Udemy:
Simple Consumer
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class ConsumerDemo {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(ConsumerDemo.class.getName());
String bootstrapServers = "localhost:9092";
String groupId = "sometopic-g1";
String autoOffsetResetConfig = "latest";
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetResetConfig);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton("sometopic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
logger.info("Key: {}, Value: {}", record.key(), record.value());
logger.info("Partition: {}, Offset: {}", record.partition(), record.offset());
}
}
}
}
Consumer: Assign and Seek
This method allow us to read specific message. It is mostly used to replay data or fetch specific messages.
A Consumer can either subscribe to topics (and be part of a consumer group) or assign itself partitions - but not both at the same time
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class ConsumerDemoAssignAndSeek {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(ConsumerDemoAssignAndSeek.class.getName());
String bootstrapServers = "localhost:9092";
String autoOffsetResetConfig = "latest";
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId); //not applicable with assign()
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetResetConfig);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
//consumer.subscribe(Collections.singleton("sometopic")); //not applicable with assign()
// assign to a specific partition
// a Consumer can either subscribe to topics (and be part of a consumer
// group) or assign itself partitions - but not both at the same time
TopicPartition partitionToReadFrom = new TopicPartition("sometopic", 0);
consumer.assign(Collections.singleton(partitionToReadFrom));
// seek to specific offset
long offsetToReadFrom = 15L;
consumer.seek(partitionToReadFrom, offsetToReadFrom);
int numberOfMessagesToRead = 5;
int numberOfMessagesReadSoFar = 0;
boolean keepOnReading = true;
while (keepOnReading) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
numberOfMessagesReadSoFar++;
logger.info("Key: {}, Value: {}", record.key(), record.value());
logger.info("Partition: {}, Offset: {}", record.partition(), record.offset());
if (numberOfMessagesReadSoFar >= numberOfMessagesToRead) {
keepOnReading = false;
break;
}
}
}
logger.info("Exiting the application");
}
}
Consumer: With Threads for Better Performance and Handling
This method provides a way to work with multiple threads and an elegant way of shut down consumers.
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.errors.WakeupException;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class ConsumerDemoWithThreads {
public static void main(String[] args) {
new ConsumerDemoWithThreads().run();
}
private void run() {
Logger logger = LoggerFactory.getLogger(
ConsumerDemoWithThreads.class.getName());
String bootstrapServers = "localhost:9092";
String groupId = "sometopic-g1";
String autoOffsetResetConfig = "earliest";
// latch for dealing with multiple threads
CountDownLatch latch = new CountDownLatch(1);
logger.info("Creating the consumer thread");
ConsumerRunnable runnable = new ConsumerRunnable(
bootstrapServers, groupId, "sometopic", autoOffsetResetConfig, latch);
new Thread(runnable).start();
// add a shutdown hook
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
logger.info("Caught shutdown hook");
runnable.shutdown();
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
logger.info("Application has exited");
}));
try {
latch.await();
} catch (InterruptedException e) {
logger.error("Application got interrupted", e);
} finally {
logger.info("Application is closing");
}
}
public class ConsumerRunnable implements Runnable {
private CountDownLatch latch;
private Logger logger = LoggerFactory.getLogger(ConsumerRunnable
.class.getName());
private final String bootstrapServers;
private final String groupId;
private final String topic;
private String autoOffsetResetConfig;
private KafkaConsumer<String, String> consumer;
public ConsumerRunnable(String bootstrapServers, String groupId,
String topic, String autoOffsetResetConfig, CountDownLatch latch) {
this.bootstrapServers = bootstrapServers;
this.groupId = groupId;
this.topic = topic;
this.autoOffsetResetConfig = autoOffsetResetConfig;
this.latch = latch;
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
bootstrapServers);
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,
autoOffsetResetConfig);
this.consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singleton(topic));
}
@Override
public void run() {
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(
Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
logger.info("Key: {}, Value: {}", record.key(),
record.value());
logger.info("Partition: {}, Offset: {}",
record.partition(), record.offset());
}
}
} catch (WakeupException e) {
logger.info("Received shutdown signal");
} finally {
consumer.close();
// tell the main code we're done with the consumer
latch.countDown();
}
}
public void shutdown() {
// to interrupt consumer.poll()
// it will throw WakeUpException
consumer.wakeup();
}
}
}
CLI: important commands to know
Consumer commands
# read new data from a particular topic
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
--topic sometopic
# read data from a particular topic (from the beginning)
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
--topic sometopic --from-beginning
# read new data from a particular topic (with keys)
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
--topic sometopic --property print.key=true --property key.separator=,
# read new data from a particular topic (and saving it in a file)
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
> sometopic_output.txt
Consumer group commands
# read data from a topic using consumer groups
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
--topic sometopic --group sometopic-g1
# list available consumer groups
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
# describe a consumer group for all topics
# (here you can see offsets size, current position and lags)
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092
--group sometopic-g1 --describe
# reset the offset (to earliest) for a particular consumer group's topic
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092
--group sometopic-g1 --topic sometopic --reset-offsets --to-earliest --execute
# reset the offset (get back two positions) for a particular consumer group's
# topic
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092
--group sometopic-g1 --topic sometopic --reset-offsets --shift-by -2 --execute
# reset the offset (get back one position) for a particular consumer group's
# topic and partition
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092
--group sometopic-g1 --topic sometopic:0 --reset-offsets --shift-by -1 --execute