Kafka Connect Concepts
Review of the connect concepts in Apache Kafka.
Kafka is a distributed, resilient, fault tolerant streaming platform that works with high data throughput. In this page, the main concepts of Kafka Connect technology will be covered.
- What are Kafka Connectors
- Why to Use Kafka Connect
- Kafka Connect High-Level Overview
- Connectors and Tasks
- Sources and Sinks
- Common Use Cases
- Workers
- Cluster and Distributed Architecture
- Running a Standalone Worker to Read a File and Send it to Kafka
- Available REST APIs for Kafka Connect
- Running the Same File Reading in Distributed Mode
- Sink: Saving Topic Contents to a File
- Where Can I Get More Connectors?
- Write your Own Connector
- Kafka Connect Transformations
- How to Build a Connector and Run it in Kafka
- How to Run Connectors in Production
- Landoop: Easier Kafka Connect Administration Tool
- References
What are Kafka Connectors
Kafka Connectors are components that make it easier to programmers to get and send data to/from external sources or sink to/from Kafka Cluster.
Those are bridges between Kafka Cluster and the external world.
Why to Use Kafka Connect
- Simplifies common actions that programmers usually do (reading data to send to Kafka, get data from Kafka and save it elsewhere)
- Promote reuse of common problems (since it’s a component)
- Some issues are hard to solve in programming (ditributed ordering, exacly once, etc), and it is usually better to use a common connector that already solve these problems, instead of solve those from scratch
Kafka Connect High-Level Overview
In a high overview, Kafka Connect interacts with Kafka in the following way:
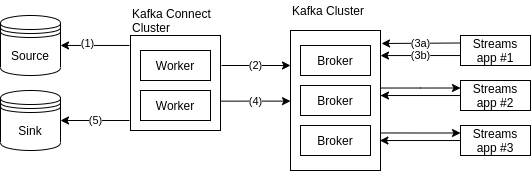
Figure: Kafka Connnect Overview.
As described in the previous diagram:
- step 1. Kafka Connector Source (running into a Cluster) get data from source (external)
- step 2. Kafka Connector Source sends collected data to Kafka Cluster (acting like a producer in that regard)
- step 3a. Kafka client application (acting as consumer) read data from Kafka Cluster
- step 3b. Kafka client application (now acting as producer) send processed data to Kafka Cluster
- step 4. Kafka Connector Sink (running into a Cluster) read data from Kafka Cluster (acting like a consumer in that regard)
- step 5. Kafka Connector Sink send read data into a sink (external)
Connectors and Tasks
Connectors are responsible to manage the tasks that will run. They must decide how data will be splitted to tasks, and provide tasks with specific configuration to perform their job well.
Tasks are responsible to get things in and out of Kafka. They get their context from the worker. Once initialized, they are started with a Properties object, containing connectors configuration. Once started, the tasks poll an external source and return a list of records (and the worker will send those data to a Kafka broker).
Sources and Sinks
A connector can be a Sink, a Source, or both.
Source: acting as a producer, bringing data to Kafka from an external source- for instance: to read data from REST API (source), parse its JSON response
and send the parsed data to Kafka Cluster
- for instance: to read data from REST API (source), parse its JSON response
Sink: acting as a consumer, reading data from Kafka and saving them in an external sink- for instance: get data from Kafka Cluster and send it to Tweeter (sink) as a tweet
Common Use Cases
| Source -> Kafka | Producer API | Kafka Connect Source |
| Kafka <-> Kafka | Consumer API, Producer API | Kafka Streams |
| Kafka <- Sink | Consumer API | Kafka Connect Sink |
Workers
Connectors run inside processes called Workers. In those workers, scalability is also supported.
- Each worker is an isolated, simple Java Process (JVM)
- Workers run Connectors (each connector is class inside a
jarfile) - Worker runs Connectors’
Tasksto perform its actions- A job configuration can be composed of several tasks
- A Worker can run in standalone mode or distributed mode
- If a worker crashes, a rebalance will occur (the heartbeat mechanism in the Kafka consumer’s Protocol is applied here)
- If a worker joins a Connect cluster, other workers will notice that and assign connectors or tasks to this new worker, in order to balance the cluster.
- To join a cluster, a worker must have the same
group.idproperty.
- To join a cluster, a worker must have the same
- Workers perform
Offset Managementto the connectors, which means that connectors need to know which data has already been processed. This information is different from connector to connector (in a file connector, it may be the position of a line, and in a JDBC Connector, it may be the primary key). This decision (about how to define offset management) is very important for paralelism and in a context of semantics for a connector. Workers manage this information by using Kafka API to save data in the Kafka broker.
| Standalone Worker | Distributed Worker |
|---|---|
| A single process run both connectors and tasks | Multiple workers run connectors and tasks |
Configuration use .properties files | Configuration is performed by a REST API |
| Very easy to use; good for dev and test | Useful for production deployment |
| No fail tolerance, no scalability, hard to monitor | Easy to scale (only add new Workers), and fail tolerant (automatic rebalance in case of an inactive worker) |
Distributed workers do not necessary need to run in a cluster environment. For testing purposes, one may run several Workers in the same machine, just starting different JVMs using different properties files.
Cluster and Distributed Architecture
A Kafka Connect Cluster can handle multiple Connectors.
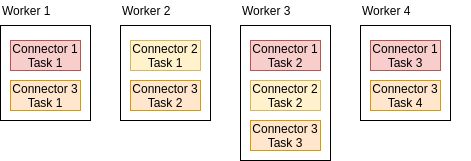
Figure: Kafka Connnect: Workers in a Cluster.
In the previous diagram:
- Each conector will have its tasks spread in the cluster workers’
- A single worker can have more than one task from the same connector
- When a Worker dies, its tasks are rebalanced to other live brokers
Running a Standalone Worker to Read a File and Send it to Kafka
Let’s run a simple worker in standalone mode to read a text file (source) and send it to the Kafka Broker. The Source Connector for a File Stream is native to Kafka, so we don’t need to import any jars for this example.
Kafka’s FileStreamSourceConnector Source code @ Github
First of all, it is necessary to create a properties file to configure this connector.
Let’s call it file-standalone.properties, with the following content:
# /home/daniel/data/kafka/connectors/file-standalone.properties
# These are standard kafka connect parameters, needed for ALL connectors
name=file-standalone
connector.class=org.apache.kafka.connect.file.FileStreamSourceConnector
tasks.max=1
# FileStremSourceConnector's properties
file=/home/daniel/data/kafka/connectors/file-to-read.txt
topic=connect-source-file-topic
Next, let’s create this file to be read (file-to-read.txt):
/home/daniel/data/kafka/connectors/file-to-read.txt
hello
using 'FileStreamSourceConnector' Kafka Connector Source to produce some data
another line produced
one more line
and thats ok for now
bye
Next step is to start Kafka in the local environment:
kafka $ ./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
kafka $ ./bin/kafka-server-start.sh -daemon ./config/server.properties
Now, we can execute the worker:
kafka $ ./bin/connect-standalone.sh ./config/connect-standalone.properties
/home/daniel/data/kafka/connectors/file-standalone.properties
- The first parameter of shell call is a property file that define workers characteristics. In that case, we’re using Kafka Default file for Kafka Connect in standalone mode
- The second parameter is the property file to our specific configuration of Kafka Connect File Stream Source Connector. You can pass as many files after the first one (the worker definition), and the second one (must have at least one connector config file), and each file will be related to a additional Sink/Source Connector.
After that, we can consume this topic and see the results:
kafka $ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic connect-source-file-topic --from-beginning
{"schema":{"type":"string","optional":false},"payload":"using
'FileStreamSourceConnector' Kafka Connector Source to produce some data"}
{"schema":{"type":"string","optional":false},"payload":"another line produced"}
{"schema":{"type":"string","optional":false},"payload":"one more line"}
{"schema":{"type":"string","optional":false},"payload":"and thats ok for now"}
{"schema":{"type":"string","optional":false},"payload":"bye"}
{"schema":{"type":"string","optional":false},"payload":"hello"}
As we can notice, all file information from source file was written in Kafka Broker as JSON (but our file is not formatted as JSON file). That is because the default Kafka file for worker properties (that define JSON as converter method) was used.
About Key and Value Converters
So, our data is being written as JSON. To understand why this is happening, let’s consider again the call to Kafka Connect in standalone mode:
kafka $ ./bin/connect-standalone.sh ./config/connect-standalone.properties
/home/daniel/data/kafka/connectors/file-standalone.properties
file-standalone.properties: this is the file that was created to explain to the worker that to do: a Kafka Source Connector must read our particular text file and send it to a topic./config/connect-standalone.properties: this is the default Kafka file, that assumes the following properties:bootstrap.servers=localhost:9092 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true offset.storage.file.filename=/tmp/connect.offsets offset.flush.interval.ms=10000
Since key.converter and value.converter pointed to a JsonConverter class, that explains why our data is being written as JSON. Naturally, this can be changed.
Changing Conversion Method
If we want to change the data format from JSON to String, for instance, the only required action is to change the value of both key.converter and value.converter properties to a String converter (org.apache.kafka.connect.storage.StringConverter).
- This properties can be changed in worker properties file, or defined in the file-standalone properties (in this case, it will override worker definition)
- After that, it is necessary to restart the worker (restart the task is not enough when it comes to change configuration). New data in the file will start to be written as Strings (instead of JSON) in a topic
# /home/daniel/data/kafka/connectors/file-standalone.properties
# These are standard kafka connect parameters, need for ALL connectors
name=file-standalone
connector.class=org.apache.kafka.connect.file.FileStreamSourceConnector
tasks.max=1
# optional: override kafka worker definition
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
# FileStremSourceConnector's properties
file=/home/daniel/data/kafka/connectors/file-to-read.txt
topic=connect-source-file-topic
kafka$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic connect-source-file-topic --from-beginning
{"schema":{"type":"string","optional":false},"payload":"hello"}
{"schema":{"type":"string","optional":false},"payload":"using
'FileStreamSourceConnector' to produce some data"}
{"schema":{"type":"string","optional":false},"payload":"another line produced"}
{"schema":{"type":"string","optional":false},"payload":"one more line"}
{"schema":{"type":"string","optional":false},"payload":"and thats ok for now"}
{"schema":{"type":"string","optional":false},"payload":"bye"}
{"schema":{"type":"string","optional":false},"payload":"and back"}
{"schema":{"type":"string","optional":false},"payload":"and forth"}
{"schema":{"type":"string","optional":false},"payload":"and again?"}
{"schema":{"type":"string","optional":false},"payload":"and again!"}
xaxaxa xamps ## new data arrived as plain String
When and how the file is reprocessed?
While the file do not change, it will not be processed again. Only new lines will be processed in this connector. After addition, there are two ways to make the new lines to be processed:
- stop and start the worker
- only restart the specific task related to that connector, using REST API:
$ curl -X POST localhost:8083/connectors/file-standalone/tasks/0/restart
Available REST APIs for Kafka Connect
The following commands use curl for http requests and jq in order to parse json for human-readable format.
# To get cluster information:
$ curl localhost:8083 | jq # GET verb is default
# To get a list of components already installed into the cluster:
$ curl localhost:8083/connector-plugins | jq
# To list all connectors:
$ curl localhost:8083/connectors | jq
# To get data about a single connector:
$ curl localhost:8083/connectors/<connector-name> | jq
# To check properties of a single connector
$ curl localhost:8083/connectors/<connector-name>/config | jq
# To get data of a single connector tasks:
$ curl localhost:8083/connectors/<connector-name>/tasks | jq
# To get status of a single connector:
$ curl localhost:8083/connectors/<connector-name>/status | jq
# To control the execution of a connector
$ curl -X PUT localhost:8083/connectors/<connector-name>/pause
$ curl -X PUT localhost:8083/connectors/<connector-name>/resume
# To delete a connector
$ curl -X DELETE localhost:8083/connectors/<connector-name>
# To create a new connector using inline json config
$ curl -X POST -H "Content-type: application/json" --data \
'{"name": "connector-name", "config": { "connector.class":"FileStreamSourceConnector", "tasks.max":"1", "file":"somefile.txt", "topic":"sometopic" }}' \
localhost:8083/connectors | jq
# To create a new connector using json file config
$ echo '{"name": "connector-name", "config": { "connector.class":"FileStreamSourceConnector", "tasks.max":"1", "file":"somefile.txt", "topic":"sometopic" }}' \
| jq > config.json
$ curl -X POST -H "Content-type: application/json" --data @config.json \
localhost:8083/connectors | jq
# To update a connector configuration
$ curl -X PUT -H "Content-type: application/json" --data "<config as json>" \
localhost:8083/connectors/<connector-name>/config
# To control the execution of specific task:
$ curl -X POST localhost:8083/connectors/<connector-name>/tasks/<task-id>/restart
PUT and POST Methods
The GET and DELETE methods are self explanatory, but it’s confusing to understand the usage of PUT and POST methods.
It seems like Kafka adopts PUT method when there is idempotency on the server side (which means, no collateral effects will raise in terms of data change). For instance, if you change a configuration of a connector, this will not trigger any action that will change data in the context of a resource.
Of course, config data will be saved internally - but, in this context, being idempotent means to change the behavior of resource itself (and not to change in terms of file writing). You will change the property of a connector, but this will not start any real action, so it is idempotent. But if you tell a task to restart, that will execute code that can actually do something (read again the source file and process changes, for instance).
And Kafka adopts POST Method when the resource actually performs noticeable change. For instance, when restarting a task, it will trigger a worker to restart and run code.
Considering this definition, the following REST API actions must be called by PUT Method:
- change a configuration of a connector - triggers no action
- pause and resume a connector - triggers no action in the tasks
And the following REST API actions must be called by using POST Method:
- create a new connector - trigger execution actions by tasks
- restart and pause a task - trigger execution actions
Running the Same File Reading in Distributed Mode
Let’s consider two different workers. To Kafka, it doesn’t matter if they are running in the same machine or in two different machines (which is required for Kafka brokers). So, a single broker can have more than one worker - and that makes the testing job a lot easier, because no cluster is required to validate distributed worker mode.
Of course, in production environment you want to make sure that workers are running in different brokers, to get all the benefits of a cluster (scalability, availability, etc).
Start a Distributed Worker
A distributed worker can be run by executing the following command:
$ ./bin/connect-distributed.sh -daemon config/connect-distributed.properties
Unlike connect-standalone.sh, there is no param to inform the connector property file. That is because, in distributed mode, the connector properties manipulation must be entirely done via REST API.
How to Run More Than One Worker?
Each worker starts its own JVM process, so you can run multiple executions of the above command. However, you have to use different properties files. Example:
# start first worker - nothing different
$ ./bin/connect-distributed.sh -daemon config/connect-distributed.properties
# start second worker (using different properties file)
$ ./bin/connect-distributed.sh -daemon config/connect-distributed-2.properties
More on that on the next section.
connect-distributed.properties file in depth
You must have different connect-distributed.properties files for each worker when running in the same broker. Some of the most important properties in that regard are the following:
bootstrap.servers=localhost:9092- All your workers must share this configuration, since they are running in the same cluster (and have to find same Kafka Brokers)
group.id=connect-cluster- All your workers must share this configuration, because this is required for all the workers that belong to the same cluster
- Storage properties: Since we’re working on a cluster, Kafka create topics to store connectors data. The replication factor must be changed according to the number of brokers. All of these properties must be the same between the workers (or things may go wrong)
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1 # use value -1 for kafka defaults
offset.storage.partitions=-1 # use value -1 for kafka defaults or do not inform
config.storage.topic=connect-configs
config.storage.replication.factor=1 # use value -1 for kafka defaults
# config.storage topic must have exactly 1 partition and this cannot be changed!
status.storage.topic=connect-status
status.storage.replication.factor=1 # use value -1 for kafka defaults
offset.storage.partitions=-1 # use value -1 for kafka defaults or do not inform
rest.port=8084- This is the port to be used to perform REST API executions. It must be different for each worker if running in the same machine, and may be the same in workers running in different machines.
plugin.path=<some path to plugins dir>- When working with different connectors, the jar files must be put in a directory and then referenced here
So, to run different workers in the same broker, use different connect-distributed.properties files, and only change the property called rest.port, so each JVM can be operate in isolation, by using different ports.
To run different workers in different brokers, adjust the replication factor property.
Running in Distributed Mode with Two Workers
Consider the config.json file with the following content:
{ "name": "file-standalone",
"config": {
"connector.class":"FileStreamSourceConnector",
"tasks.max":"1",
"file":"/home/daniel/data/kafka/connectors/file-to-read.txt",
"topic":"connect-source-file-topic"
}
}
Let’s start two workers using different property files:
# start first worker - rest.port set as 8084
$ ./bin/connect-distributed.sh -daemon config/connect-distributed.properties
# start second worker - rest.port set as 8085
$ ./bin/connect-distributed.sh -daemon config/connect-distributed-2.properties
And now that workers are running, let’s use workers’ REST API to configure our connector. The following code create a connector using one worker and verify that creation using another worker.
# create a connector in the worker which REST is at 8084
$ curl -X POST -H "Content-type: application/json" --data @config.json \
localhost:8084/connectors |jq
# checking that config was replicated in the worker which REST is 8085
$ curl localhost:8085/connectors | jq
All of these commands happened on the same Kafka Broker, but they should be run in different brokers, exactly the same way.
Distributed Mode: Use Case Overview
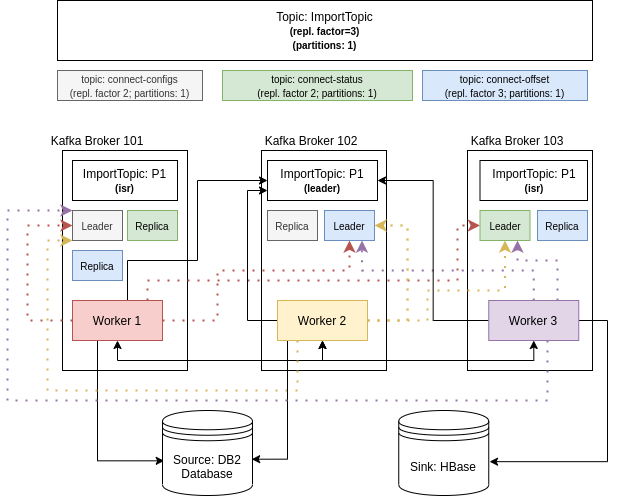
Figure: Kafka Connnect: Distributed Mode in a Cluster.
In the figure above, the ImportTopic is used to import data to HBase from mainframe (DB2 database).
So, Kafka Connector is being used to move data from DB2 database to HBase. Two workers have Source Connectors (to read data from BD2 and send those data to a topic called ImportTopic), and a single worker have a Sink Connector (to write data from ImportTopic into HBase). The ImportTopic has only one partition, and replication factor of three.
Each worker interacts with a partition Leader of ImportTopic, as if they were a Kafka Client (producer or consumer) - in fact, they are. They also interact with the Partition Leader of internal topics (connect-config, connect-status and connect-offset), so the metadata is properly shared between workers.
Sink: Saving Topic Contents to a File
If we check our available connector plugins ($ curl localhost:8084/connector-plugins | jq), we will realize that there are also a FileStreamSinkConnector. It means that we can write file from Kafka to a file out-of-the-box, without any connector installation.
So let’s do it. The required actions to do so are the following:
- Configure a new Sink connector in Kafka Connect Worker
- Check if the file was created with the expected content
That easy.
Configuring a new Sink Connector
Given a filesink.json file with the content:
{
"name": "file-standalone-sink",
"config": {
"connector.class":"FileStreamSinkConnector",
"tasks.max":"1",
"file":"/home/daniel/data/kafka/connectors/file-sink.txt",
"topics":"connect-source-file-topic"
}
}
Unlike the FileStreamSourceConnector config, the property to set the topic is “topics” (and not “topic”).
Run the following command:
$ curl -X POST -H "Content-type: application/json" --data @filesink.json \
localhost:8084/connectors | jq
But will give us an error. Because out topic is a mix of JSON and plain text content, the SinkConnect cannot parse data properly.
What we have to do is to delete a topic, change the content of source file, and then restart the sink and source connectors.
$ kafka-topics.sh --bootstrap-server localhost:9092 --topic \
connect-source-file-topic --delete
$ vim file-to-read.txt
<add some new lines>
$ curl -X POST localhost:8085/connectors/file-standalone/tasks/0/restart
$ curl -X POST localhost:8085/connectors/file-standalone-sink/tasks/0/restart
$ cat file-to-read.txt file-standalone-sink.txt
The sink connector stores lines in the sink file as expected. The content format is plain text (and not JSON). This must be weird, because the kafka-console-consumer presents data as JSON.
Since we do not define any converter in our connectors, the default was used (JSON Converters, defined in the worker). This converter was applied to both source and sink connectors.
So, considering the default converter (JSON), data is read as text and transformed to JSON (source), and then is read as JSON and parsed as text - the original value (sink).
If we want to write our data in sink file as it is in the topic (as JSON), it is necessary to define the value.converter sink property to a String. That way, data will be not converted from json, and be returned as it is.
Given a file filesink-config.json with the content:
{
"connector.class":"FileStreamSinkConnector",
"tasks.max":"1",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"file":"/home/daniel/data/kafka/connectors/file-sink.txt",
"topics":"connect-source-file-topic"
}
Run the following commands to update config and restart the task:
$ vim file-to-read.txt
<add some new lines>
$ curl -X PUT -H "Content-type: application/json" --data @filesink-config.json \
localhost:8084/connectors/file-standalone-sink/config | jq
$ curl -X POST localhost:8084/connectors/file-standalone-sink/tasks/0/restart
$ curl -X POST localhost:8084/connectors/file-standalone/tasks/0/restart
$ cat file-standalone-sink.txt
After that, the new content of file-standalone-sink should be written as JSON.
Where Can I Get More Connectors?
Write your Own Connector
That’s the fun part.
Using a Maven Archetype
Consider using the Jeremy Custenborder Maven Archetype for Kafka Connectors.
Dependencies (pom.xml)
The project created by using jcustenborder Maven archetype has, in its pom.xml, an inheritance from com.github.jcustenborder.kafka.connect:kafka-connect-parent. That POM uses org.apache.kafka:connect-api dependency. This dependency provides us three classes (that we need to extend):
org.apache.kafka.common.config.AbstractConfigorg.apache.kafka.connect.source.SourceConnectororg.apache.kafka.connect.source.SourceTask
We’ll cover those in depth in the next sections.
org.apache.kafka:connect-api has the org.apache.kafka:kafka-clients dependency (and that allows connector to behave like a consumer/producer client).
Anatomy of a Connector
This section will analyze the three classes that should be extended in order to create a new Kafka Connector. The examples here presented were extracted from my kafka-connect-covid19api project.
AbstractConfig
This class can be extended to provide specific configuration for our Connector. The constructor must be override in order to inform a specific org.apache.kafka.common.config.ConfigDef which provide the configuration:
package com.arneam;
import com.github.jcustenborder.kafka.connect.utils.config.ConfigKeyBuilder;
import java.util.Map;
import org.apache.kafka.common.config.AbstractConfig;
import org.apache.kafka.common.config.ConfigDef;
import org.apache.kafka.common.config.ConfigDef.Type;
public class Covid19SourceConnectorConfig extends AbstractConfig {
public static final String TOPIC_CONFIG = "topic";
private static final String TOPIC_DOC = "Topic to store Covid19 API data";
public static final String POLL_INTERVAL_MS_CONFIG = "poll.interval.ms";
private static final String POLL_INTERVAL_MS_DOC = "Time between two calls to Covid19API";
public final String topic;
public final Long pollIntervalMs;
public Covid19SourceConnectorConfig(Map<?, ?> originals) {
super(config(), originals);
this.topic = this.getString(TOPIC_CONFIG);
this.pollIntervalMs = this.getLong(POLL_INTERVAL_MS_CONFIG);
}
public static ConfigDef config() {
return new ConfigDef()
.define(ConfigKeyBuilder.of(TOPIC_CONFIG, ConfigDef.Type.STRING)
.documentation(TOPIC_DOC)
.importance(ConfigDef.Importance.HIGH)
.build())
.define(ConfigKeyBuilder.of(POLL_INTERVAL_MS_CONFIG, Type.LONG)
.defaultValue((long) (24 * 60 * 60 * 1000))
.documentation(POLL_INTERVAL_MS_DOC)
.importance(ConfigDef.Importance.HIGH)
.build());
}
}
SourceConnector
Once we have an AbstractConfig specialization, we must use it in our SourceConnector. This connector file basically allow us to define:
- config class to be used (in our case, the previously defined
Covid19SourceConnectorConfigclass) - task class to be used (more on that in the next section)
package com.arneam;
import com.github.jcustenborder.kafka.connect.utils.VersionUtil;
import com.github.jcustenborder.kafka.connect.utils.config.Description;
import com.github.jcustenborder.kafka.connect.utils.config.DocumentationImportant;
import com.github.jcustenborder.kafka.connect.utils.config.DocumentationNote;
import com.github.jcustenborder.kafka.connect.utils.config.DocumentationTip;
import com.github.jcustenborder.kafka.connect.utils.config.Title;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.kafka.common.config.ConfigDef;
import org.apache.kafka.connect.connector.Task;
import org.apache.kafka.connect.source.SourceConnector;
@Description("Connect to Covid19API to get Covid19 data of all countries in the world")
@DocumentationImportant("")
@DocumentationTip("")
@Title("Kafka-Connect-Covid19API")
@DocumentationNote("Note: use it in conjunction with 'kafka-streams-covid19api' application")
public class Covid19SourceConnector extends SourceConnector {
private Covid19SourceConnectorConfig config;
@Override
public String version() {
return VersionUtil.version(this.getClass());
}
@Override
public void start(Map<String, String> map) {
this.config = new Covid19SourceConnectorConfig(map);
}
@Override
public Class<? extends Task> taskClass() {
return Covid19SourceTask.class;
}
@Override
public List<Map<String, String>> taskConfigs(int i) {
List<Map<String, String>> configs = new ArrayList<>(1);
configs.add(config.originalsStrings());
return configs;
}
@Override
public void stop() {
}
@Override
public ConfigDef config() {
return Covid19SourceConnectorConfig.config();
}
}
SourceTask
This is the class that performs all the work. It must be override to perform the required action in its poll() method. Basically, four methods need to be overriden:
version(): component versionstart(): starts a component; usually loads the config objectstop(): action to perform when the component is stoppedpoll(): the most important one. It it responsible por generate a list oforg.apache.kafka.connect.source.SourceRecordthat will be used to poll the messages to the Kafka Broker (this is a Source Connector). The object construction takes a lot of elements, as can be seen below:
package com.arneam;
// import ...;
public class Covid19SourceTask extends SourceTask {
private static Logger log = LoggerFactory.getLogger(Covid19SourceTask.class);
// some attributes
@Override
public String version() {
return VersionUtil.version(this.getClass());
}
// when start, load a config
@Override
public void start(Map<String, String> map) {
config = new Covid19SourceConnectorConfig(map);
}
@Override
public void stop() {
}
@Override
public List<SourceRecord> poll() throws InterruptedException {
// <deleted code, for the sake of simplicity>
List<SourceRecord> records = new ArrayList<>();
JSONArray countries = getCovid19APICountries(1);
log.info("-----> Total of countries: {}", countries.length());
this.sendDummy = true;
return recordsFromCountries(records, countries);
}
// <deleted code, for the sake of simplicity>
private SourceRecord generateSourceRecordFrom(Country country) {
return new SourceRecord(sourcePartition(), sourceOffset(), config.topic, null,
Covid19Schema.KEY_SCHEMA, buildRecordKey(country), Covid19Schema.VALUE_SCHEMA,
buildRecordValue(country), Instant.parse(country.getDate()).toEpochMilli());
}
private Map<String, String> sourcePartition() {
Map<String, String> map = new HashMap<>();
map.put("partition", "single");
return map;
}
private Map<String, String> sourceOffset() {
Map<String, String> map = new HashMap<>();
map.put("timestamp", String.valueOf(Instant.now().toEpochMilli()));
return map;
}
private Struct buildRecordKey(Country country) {
return new Struct(Covid19Schema.KEY_SCHEMA)
.put(Covid19Schema.DATE_FIELD, country.getDate());
}
private Struct buildRecordValue(Country country) {
return new Struct(Covid19Schema.VALUE_SCHEMA)
.put(Covid19Schema.COUNTRY_FIELD, country.getCountry())
.put(Covid19Schema.COUNTRY_CODE_FIELD, country.getCountryCode())
.put(Covid19Schema.SLUG_FIELD, country.getSlug())
.put(Covid19Schema.NEW_CONFIRMED_FIELD, country.getNewConfirmed())
.put(Covid19Schema.TOTAL_CONFIRMED_FIELD, country.getTotalConfirmed())
.put(Covid19Schema.NEW_DEATHS_FIELD, country.getNewDeaths())
.put(Covid19Schema.TOTAL_DEATHS_FIELD, country.getTotalDeaths())
.put(Covid19Schema.NEW_RECOVERED_FIELD, country.getNewRecovered())
.put(Covid19Schema.TOTAL_RECOVERED_FIELD, country.getTotalRecovered())
.put(Covid19Schema.DATE_FIELD, country.getDate());
}
}
There are a lot to cover. It is recomended to check the kafka-connect-covid19api project code for a complete functional example.
Kafka Connect Transformations
Kafka Connectors can be configured to use transformations. These are handy to perform small modifications on messages.
More information about Connector transformations can be found in Kafka Documentation Page.
How to Build a Connector and Run it in Kafka
These are simple steps to register a previous connector in Kafka Connect:
- Package the Java Maven project:
$ mvn clean package - Copy the directory
target/kafka-connect-target/usr/share/kafka-connect/kafka-connect-covid19apito the same directory specified by the propertyplugins.pathin the Kafkaconnect-distributed.propertiesfile (orconnect-standalone.propertiesfile) - Start a Kafka Connect Worker
- Register the Connector using REST API and start the connector
- the JSON to be used for connector configuration can be found in README.md file
# save connector properties in a file (let's call it: config.json)
# run the following command to create a Kafka Connector configuration into
# the Cluster
$ curl -X POST -H "Content-type:application/json" --data @config.json \
localhost:8084/connectors | jq
- Consume a Kafka topic to make sure that Covid19-API data was actually read from the API and then produced into the topic:
$ kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic x \
--from-beginning
You may see a lot of JSON messages, one for each country. And that’s it for this connector.
A Kafka Streams app would be responsible to read this raw data and generates consolidated information. Actually, this performed in my project ‘kafka-streams-covid19api’, that consolidate this countries’ data to rank Brazil position related to the world.
How to Run Connectors in Production
- There is no difference that what was said in the previous sections
- Consider distributed mode
- Each Kafka Broker machine in the cluster can run one or more workers
- If running in the same box, change
rest.portproperty for obvious reasons
- If running in the same box, change
- Distribute its workers between different machines for failure tolerance
- Each Kafka Broker machine in the cluster can run one or more workers
- Consider tools to improve Workers’ administration
- Landoop for a interface to manage connectors
- It uses Kafka Connector REST API internally
- Its web interface make the work easier
- Docker to run Landoop (if applicable)
- Landoop for a interface to manage connectors
Landoop: Easier Kafka Connect Administration Tool
Landoop is a tool to make it easy to manage Kafka Connect workers.
- There is a docker image to make the usage simple (landoop/fast-data-dev)
- default URL: http://localhost:3030